


Beyond the Root: Mastering the Technical Self-Mirror
Some labs reward speed and leave judgment untouched. Kioptrix Level 1 is useful for the opposite reason: it is small, old, and honest enough to show you where your technical self-assessment breaks before your confidence starts writing fiction.
The real friction for many beginners and rusty practitioners isn’t a lack of tools, it’s the uncertainty of progress. Are your enumeration and note-taking actually improving, or just getting louder? This guide turns one modest lab into repeatable evidence of growth through practical review habits: evidence tracking, branch decisions, and after-action debriefs.
“Root is not the whole story. Your notes are part of the score. And the most useful clue may be the moment your thinking goes sideways.”
Keep reading, because that is where the real training begins.
Table of Contents
There is a reason older labs still matter. They are not trendy. They are not trying to impress you. They do not arrive wrapped in cinematic difficulty curves and neon scoreboard energy. They simply sit there and ask a blunt question: What do you actually do when you do not know what to do next? That question has hired more good security people than raw speed ever did.
Start Here First: Why Kioptrix Is Good for Self-Assessment, Not Just Exploitation Practice
The lab is small enough to reveal your habits, not hide them
Kioptrix works well for self-assessment because it narrows the room. In a huge environment, weak habits can hide under the carpet. In a smaller lab, they clatter loudly. You notice when you scanned too broadly, when you skipped note-taking, when you assumed a service mattered because it looked familiar, and when you ran one more tool mostly because silence felt awkward. Small labs are impolite that way. They expose your habits with fluorescent honesty.
I have seen learners confuse “more moving parts” with “more learning.” Usually it is the reverse. When the surface area is modest, your own decision-making becomes easier to inspect. That is exactly what you want if your goal is technical self-assessment. You are not trying to stage a fireworks show. You are trying to catch the moment where your reasoning slips on a wet tile.
A narrow target makes weak reasoning easier to spot
In a compact lab, your choices matter more because there are fewer places to hide. If you miss a clue, that miss has shape. If you jump to an exploit path too early, you can trace the impatience. If you keep re-running enumeration because it feels productive, you can see the loop with almost comic clarity. The lab becomes less of a puzzle box and more of a behavior camera.
That matters because mature self-assessment is not moral theater. It is not standing in front of your own work and shouting “good job” or “you are terrible.” It is simpler and harder than that. It is asking: What did I observe? What did I infer? What did I assume? What did I borrow from memory without verifying?
Why “I solved it” is not the same as “I assessed myself honestly”
A completed lab can flatter you. Completion is tidy. It closes the browser tabs. It gives the session a medal. Honest self-assessment is less decorative. It asks whether your process was legible, explainable, and repeatable. Those are different questions.
Many people “solve” a box by stumbling into the right path with a blend of memory, luck, and stubbornness. That can still teach something, but it should not be mistaken for clean assessment. The point of Kioptrix, in this frame, is not the trophy at the end. The point is the trail you leave behind.
- Small scope makes reasoning easier to inspect
- Weak note-taking shows up fast
- Outcome and process are not the same thing
Apply in 60 seconds: Before your next run, write one sentence: “Today I am measuring my process, not just my finish.”
The Real Skill: What Technical Self-Assessment Actually Means in Practice
It is not confidence, and it is not self-criticism
Technical self-assessment has a branding problem. People hear the phrase and imagine either inflated confidence or bruised self-judgment. Neither helps. Good self-assessment is an evidence practice. It is quiet, almost clerical. You are not trying to feel impressive. You are trying to become accurate.
That accuracy matters in cybersecurity because uncertainty is normal. You will often know some things, suspect others, and wish the machine would simply hand over a handwritten confession. It never does. So the skill becomes learning how to map certainty levels without panic or vanity. That is a career skill, not just a lab skill.
It means measuring decisions, evidence, blind spots, and recovery
When people say they want to improve technically, they often mean they want more commands. Commands matter, sure, but self-assessment cares more about the chain between observation and action. Why did you choose that service to inspect first? Why did you trust that result? Why did you stop one branch and pursue another? Why did confusion make you go faster instead of slower?
I once watched a learner spend 25 minutes rerunning scans because the repeated output felt comforting. That was not a tool problem. It was a self-assessment problem. The missing skill was recognizing, in real time, “I am using activity to avoid uncertainty.” That sentence can save more time than another alias ever will.
Strong learners ask, “What did I know at that moment?”
This is one of the cleanest questions you can use. It forces you to grade yourself by the evidence available then, not by the solution you learned later. That distinction matters. After you read a walkthrough, the path becomes unnaturally obvious. Memory edits the weather. The fog vanishes. Self-assessment needs the fog back.
A good review sounds like this: “At 14 minutes, I knew ports X and Y were open, I had one clue pointing toward service Z, and I chose branch A because it fit the evidence better than B.” A weak review sounds like this: “I mean, I kind of knew it would probably be that.” The second version is how the brain applies makeup to confusion.
Show me the nerdy details
Frameworks like the NICE Framework from NIST are useful here because they describe cybersecurity work in terms of tasks, knowledge, and skills rather than terminal theatrics. In practice, that means you can review your session by capability area: observation, testing logic, documentation quality, and recovery after error.
Decision card:
When A: You want to feel capable right now. You chase progress markers, fast scans, and early exploit attempts.
When B: You want to improve reliably. You pause to label evidence, assumptions, and gaps before taking the next step.
Time trade-off: A feels faster in the first 20 minutes. B usually saves time across the full session.
Neutral next step: Choose one branch on purpose and write down why you chose it.
Who This Is For and Not For
Best for beginners, career changers, and rusty practitioners rebuilding method
This approach is especially useful if you are trying to build method without drowning in complexity. Beginners benefit because Kioptrix gives them a target small enough to study without the cognitive stampede. Career changers benefit because self-assessment turns scattered effort into something measurable. Rusty practitioners benefit because it restores discipline that may have drifted after months of passive reading or stop-start study routines.
If your schedule is fragmented, this matters even more. Many people do not have four uninterrupted hours and a noise-free apartment with cinematic hacker lighting. They have 45 minutes after work, lukewarm tea, and a browser tab that still contains yesterday’s grocery list. A self-assessment frame respects that reality because it rewards consistency over drama.
Useful for intermediate learners who rush and want cleaner judgment
Intermediate learners often hit a strange wall. They know enough commands to move quickly, but not always enough discipline to move cleanly. They can generate motion, but motion is not the same thing as thought. Kioptrix becomes valuable here because it slows the vanity loop. It says, politely but firmly, “Wonderful. Now explain why you did that.”
That explanation step is often where the real gap appears. Not ignorance, exactly. More like a fuzzy bridge between tool familiarity and decision quality. Once you see that gap, you can work on it. Before that, it just feels like random inconsistency.
Not ideal for people who only want novelty, speed, or CTF-style chaos
If you want constant novelty, this approach may feel too quiet. If you want speed alone, it may feel annoyingly reflective. If you want CTF-style twists every six minutes, Kioptrix may look almost plain. That is fine. Not every lab must do every job.
But if your real goal is to become the kind of practitioner who can explain a path, justify a choice, recover from a miss, and talk about your process in an interview without sounding like you swallowed a tool manual, this method earns its keep.
Eligibility checklist
- Yes: You want to measure progress honestly, not cosmetically
- Yes: You can tolerate repeating the same box to compare process
- Yes: You are willing to document dead ends instead of hiding them
- No: You only care about novelty or leaderboards
- No: You consider note-taking an insult to your natural genius
Neutral next step: If you matched at least three “Yes” items, run one session using a written rubric.
Before You Scan: Set a Baseline You Can Actually Compare Against
Define what “good performance” means before touching the target
One of the easiest ways to lie to yourself is to start without a baseline. Then everything becomes vibes. Maybe today felt better. Maybe worse. Maybe you were “kind of sharper.” That is not an assessment. That is weather reporting. You need something more stubborn.
Before you touch the lab, define what counts as good performance for this session. Not grandly. Not academically. Just clearly. For example: “I want complete first-pass notes on open services within 15 minutes.” Or: “I want to distinguish verified facts from guesses in real time.” Or: “I want to avoid reading any hint until I have documented three plausible branches.”
Track time, note quality, hypothesis quality, and restraint
These four categories are practical because they reveal different failure modes. Time shows pacing. Note quality shows whether your future self will be able to understand what happened. Hypothesis quality shows whether your thinking is narrowing sensibly. Restraint shows whether you can resist premature exploitation, random tool spam, or early walkthrough peeking.
The category that surprises most people is restraint. They assume restraint is passive. It is not. It is an active skill. The ability to not jump at the first shiny path is often what separates useful self-assessment from noisy roleplay.
Choose a scoring lens: technical, procedural, or reflective
You do not need one master score. In fact, one score is often too blunt. Use a lens. A technical lens grades the mechanics: did you identify relevant services, inspect them sensibly, and build a plausible path? A procedural lens grades your workflow: were your notes usable, your timestamps present, your branches labeled, your steps repeatable? A reflective lens grades your awareness: did you catch assumptions, label confusion, and explain pivots honestly?
On one of my own repeats of a small lab years ago, my technical score looked fine and my reflective score looked embarrassing. I had done several useful things and understood almost none of my own pacing decisions. That was not failure. That was a gift wrapped in mild irritation.
The trick is not to sprint around the circle. It is to notice where the loop breaks. Most learners do fine at Observe and Test. The leaks usually appear in Note, Hypothesize, or Review.
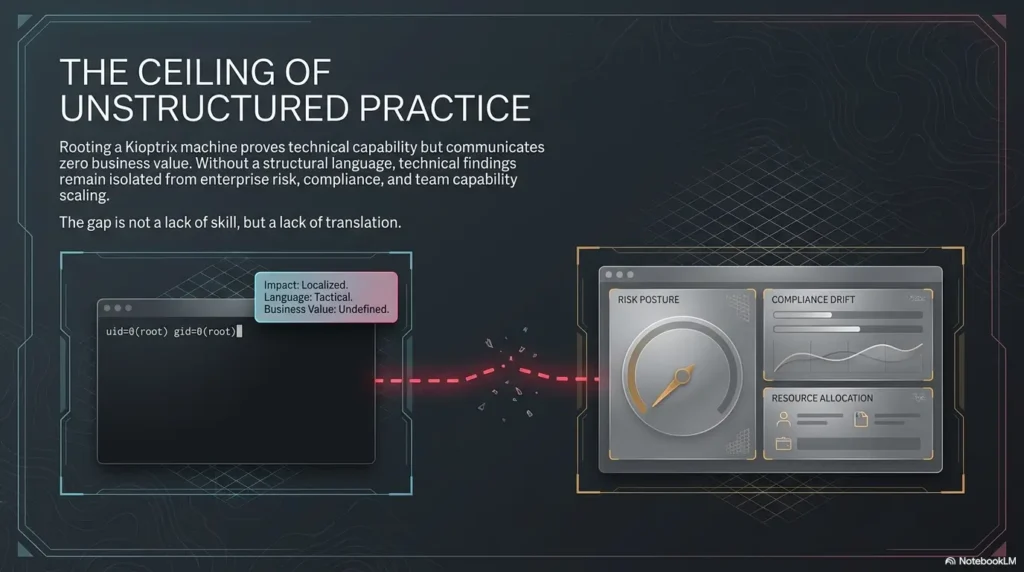
The First Mirror: What Enumeration Reveals About Your Thinking
Fast scans often expose impatience more than skill
Enumeration is where self-assessment becomes deliciously uncomfortable. Everyone says enumeration matters. Fewer people admit how much personality leaks into it. Some learners rush because speed feels professional. Some scan endlessly because activity feels safe. Some grab the output they expected and stop reading as soon as their brain hears a familiar tune. This is not a technical gap alone. It is a thinking gap wearing technical clothes.
Kioptrix is excellent here because the environment is small enough that your enumeration style becomes visible quickly. If you miss something, it often traces back to pacing, attention, or note quality rather than exotic complexity. That is actually good news. Fixing attention is cheaper than fixing destiny.
Missing small clues usually points to attention drift, not bad luck
When people talk about misses, they often use language that makes it sound meteorological. “I just didn’t catch it.” Maybe. But often the truth is more concrete. You were tired. You read output diagonally. You failed to translate a clue into a next question. You had the information but did not metabolize it.
That last part matters. Enumeration is not only about collecting details. It is about turning details into better next moves. An open service is not a victory. It is a sentence fragment. Your job is to finish the sentence without inventing a novel.
Here’s what no one tells you: your notes are part of the assessment
Bad notes do not just make later review annoying. They actively distort your sense of competence. If your notes only contain commands, you may feel productive while learning almost nothing about your own decision chain. Good notes capture observations, interpretations, uncertainties, and pivots. They make your session reconstructable. A simple technical journal for repeated Kioptrix sessions can make that difference visible very quickly.
One tiny anecdote: I once revisited an older lab and found notes I had taken months earlier. The commands were there. The reasoning was not. It looked like a burglar had rifled through a toolbox and left the room. That was humbling in the best way. From then on, I stopped treating notes as an accessory and started treating them as evidence.
- Speed can hide impatience
- Notes are part of the technical work
- Clues only help if they change your next move
Apply in 60 seconds: Add two columns to your notes right now: “Why it matters” and “What I’ll test next.”
Don’t Grade the Ending: Why Root Access Can Distort Your Self-Read
A lucky exploit can hide weak process
Getting root feels conclusive. It lights up the reward centers. It tells a neat story. The trouble is that neat stories can hide ugly processes. You can succeed through luck, memory, premature hinting, or brittle steps you cannot explain the next day. That does not make the success meaningless, but it does make it insufficient as a self-assessment measure.
Think of root access as an ending, not a verdict. The verdict should come from how you got there. Did your path emerge from observed evidence? Could you reproduce it without theatrical scrambling? Could you explain the decision points without waving vaguely at “intuition”? Intuition matters, but only when it has roots.
Copy-pasting success can produce a false sense of readiness
There is a particular kind of danger in labs that are well documented. The internet is generous. Solutions exist. Hints drift into memory. Even partial recall can make you feel sharper than you really are. You remember the corridor, so you mistake that memory for navigation skill.
That is why honest self-assessment requires labels like verified, assumed, and borrowed. Borrowed knowledge is not shameful. Pretending it was your own live reasoning is the problem. If a remembered exploit path influenced you, say so. The truth remains useful. Vanity does not. For learners who want a cleaner boundary, using a structured Kioptrix level guide only after independent work helps keep the signal honest.
The better question is whether your path was explainable and repeatable
If someone asked you to replay your session tomorrow from notes alone, could you do it? Could another learner follow your reasoning and see why each step made sense at the time? If not, your process may have been thinner than the result suggests.
Repeatability sounds dry, but it is one of the warmest forms of confidence. It means your success can survive a bad mood, a long workday, and the terrible acoustics of your own self-doubt. That kind of confidence lasts longer than a lucky exploit and looks much better in a real hiring conversation.
Mini calculator: Count your last session’s major steps.
Input 1: How many steps were verified by direct evidence?
Input 2: How many were assumed because they felt likely?
Input 3: How many were borrowed from memory, hints, or prior exposure?
Output: If “assumed + borrowed” is greater than “verified,” your finish may be outrunning your method.
Neutral next step: Re-run the box and force yourself to label every step before acting on it.
Common Mistakes: The Self-Assessment Errors Kioptrix Exposes Fast
Mistaking tool output for understanding
This is the classic trap. A tool produces output, and the mind relaxes as if meaning has been delivered. But output is not understanding. It is raw material. It still needs interpretation, prioritization, and context. Without that layer, you are not really assessing yourself. You are simply standing near a very talkative machine.
One reason learners get stuck here is that tool output feels objective. It seems solid. It seems authoritative. But authority can become a hiding place. Self-assessment asks whether you knew what the result implied, what it did not imply, and what question it should have triggered next.
Confusing familiarity with competence
Recognition is sneaky. You see a service, a banner, a pattern, and your brain says, “I know this.” Maybe you do. Maybe you just know the wallpaper. Familiarity can speed good work, but it can also replace investigation with assumption. That is why a small, repeated lab is so useful. It lets you catch the places where recognition makes you careless.
In practice, competence is not “I have seen this before.” Competence is “I can explain what this likely means, what I still do not know, and what I will test next.” The difference sounds subtle. In a real session, it is enormous.
Writing down commands instead of decisions
Command logs have value. They are not worthless. But if that is all you record, your notes become a script without a plot. Later, when you review, you can see what happened without seeing why it happened. That ruins the reflective half of the lab.
Try recording decisions instead: “Ignored branch A because it relied on two assumptions.” “Chose service B because it matched the strongest clue from enumeration.” “Paused here because repeated scans were no longer adding signal.” Those statements reveal your operating model. Commands alone rarely do. A dedicated recon log template for Kioptrix or a fuller enumeration report structure can help turn raw commands into readable thinking.
Let’s be honest: “I knew that already” is often a defense reflex
This line appears the moment the solution stings your pride. You missed something, then the brain scrambles to preserve self-image. “I knew that already.” Maybe you did, in a loose atmospheric sense. But if you knew it and did not act on it, the issue is still yours. That is not an indictment. It is useful data.
One of the healthiest habits in cybersecurity learning is learning to notice the instant your ego reaches for a blanket. When that happens, do not panic. Just write the sentence more honestly: “I had partial awareness of this clue, but I did not operationalize it.” That version may bruise a little, but it teaches.
Short Story: A learner I once coached got root on a familiar box and felt great for about seven minutes. Then we reviewed the notes. The session had almost no timestamps, one branch was followed because it “looked promising,” and a key pivot turned out to be based on a hint remembered from a forum thread months earlier. At first, the learner looked crushed.
Then something better happened. The mood shifted from pride-defense to curiosity. We rebuilt the path in four columns: evidence, assumptions, decisions, misses. Suddenly the session became far more valuable than a clean first-time win would have been. The learner did not leave with a shinier story. They left with a truer one. Three weeks later, their next run was slower for the first 20 minutes and dramatically stronger by the end.
Don’t Do This: The Habits That Make Your Review Useless Later
Skipping timestamps and losing the sequence of thought
Timestamps are boring until you need them. Then they become gold. Without them, you lose pacing data. You cannot see where confusion began, where momentum built, or where you started looping. You are left with a pile of steps and no tempo. That makes it much harder to assess whether your process is improving over time.
You do not need military-grade logging. Even rough markers every 10 or 15 minutes help. The goal is not perfect surveillance of yourself. The goal is enough structure that later review can reconstruct cause and effect.
Reading walkthroughs too early and calling it “just checking”
Few habits sabotage honest self-assessment faster than premature walkthrough checking. It feels small. It feels harmless. “I’m only checking one part.” The trouble is that once a path enters your mind, your session is no longer the same session. The evidence field has changed. You cannot unspill the ink.
Use walkthroughs, yes. But use them after you have extracted the educational value from your independent run. Otherwise you are evaluating a blended session while pretending it was a solo performance. That is not evil. It is just muddy. If this is a recurring weakness, a piece on building patience in Kioptrix sessions is often more helpful than another exploit tip.
Treating dead ends like embarrassment instead of evidence
Dead ends are not proof that you are bad. They are proof that you tested something. More importantly, they reveal your model of the system. When you take a wrong branch, you learn what made it look plausible to you. That is extremely useful. A dead end with a written reason is often more valuable than a lucky success with no reflection.
I have notebooks full of dead ends. Some are elegant. Some look like a raccoon learned Bash. But they helped because they preserved the shape of my thinking. That shape is what you are trying to improve.
- Timestamps preserve pacing
- Walkthrough timing changes the session
- Dead ends are evidence, not shame
Apply in 60 seconds: Add a simple prefix to each note line: time, evidence level, and branch name.
Use Friction Well: How to Turn Stalls, Misses, and Confusion Into Useful Data
A stall tells you where your model of the system became thin
Most learners hate stalls because a stall feels like a judgment. It is not. It is a location. It shows you where your current model stopped being detailed enough to guide action. That is useful. Very useful, actually. The stall is not the enemy. The unexamined stall is.
When you hit one, ask a technical question and a reflective question. Technical: “What do I know for sure right now?” Reflective: “What feeling is pushing me toward my next move?” Sometimes the answer is curiosity. Sometimes it is impatience. Sometimes it is the small internal scream of “Please let me do something that looks productive.” That scream is a terrible architect.
Repeated misses often point to one recurring cognitive shortcut
If you keep missing similar clues across sessions, the issue is probably not random bad luck. It is usually a recurring shortcut. Maybe you overweight familiar services. Maybe you under-document web observations. Maybe you treat negative results as dead information instead of boundary-setting evidence. Patterns like these are the gold seam in self-assessment.
Once you identify one, improvement becomes more concrete. You are no longer trying to “be better at cybersecurity,” which is so vague it may as well be fog in a suit. You are trying to fix one habit, such as “I skip writing why a clue matters” or “I pivot too fast after one failed attempt.” That is workable. For many learners, a repeatable Kioptrix recon routine helps convert vague frustration into something measurable.
Failed branches can become your best training inventory
A failed branch is not just a failed branch. It is a study inventory item. It tells you what concept, service, workflow, or thought pattern needs reinforcement. Instead of filing it under shame, file it under curriculum. That one change in labeling can rescue a lot of motivation.
The really good part is this: failed branches scale. Over time, you start to build a catalog of recurring weak spots. Maybe it includes web enumeration depth, credential logic, privilege escalation pattern recognition, or simple patience. That catalog is worth more than a generic “study harder” promise.
Quote-prep list for your own review:
- What exact clue made this branch look plausible?
- What assumption was I making without proof?
- What result should have told me to stop sooner?
- What concept would have made this branch easier to judge?
Neutral next step: Turn each repeated failed branch into one small study target for the week.
Wait, Score What Exactly? A Better Rubric for Technical Self-Assessment
Score observation before exploitation
If you only score the climax, you will distort the training. Score what came first. Did you notice relevant clues? Did you separate signal from decoration? Did you avoid making the machine say more than it actually said? Observation is not glamorous, but it is the first hinge on which the rest of the session swings.
A useful observation score can be simple: 1 to 5 for completeness, prioritization, and clarity. Did you identify what mattered? Did you record it well enough to guide the next step? Could another person read your notes and understand the landscape? If not, your later success may be balanced on a wobbly chair.
Score hypothesis quality before tool quantity
Learners often overcount tools because tools are easy to count. But quantity is a noisy metric. A better score asks whether your hypotheses were plausible, evidence-linked, and testable. “I ran five things” is not impressive. “I formed two plausible hypotheses from the observed services and tested the stronger one first” is much more mature.
This is also where career-changing readers often gain ground quickly. You do not need endless tool fluency to improve here. You need cleaner thinking. That is slower at first and far more portable later.
Score recovery after mistakes, not just mistake avoidance
Mistake avoidance sounds noble, but real operators are better served by recovery skill. You will make mistakes. Everyone does. The useful question is whether you notice them, stop compounding them, and correct course with minimal drama. Recovery is one of the most underrated signals of technical maturity.
In fact, some of the strongest sessions I have seen were not error-free. They were graceful after error. The learner noticed a wrong assumption, labeled it, pivoted cleanly, and left a readable trail. That is excellent practice.
Separate what you inferred, verified, assumed, and borrowed
This four-part split is almost absurdly helpful. Verified means direct evidence supports it. Inferred means it is a reasoned conclusion from multiple clues. Assumed means it feels likely but is not yet proven. Borrowed means the idea came from memory, hints, prior reading, or outside help. Once you sort your notes this way, the session becomes much easier to assess without flattering yourself.
Show me the nerdy details
OWASP’s testing guidance remains valuable because it emphasizes structured testing logic over random activity. CISA’s cybersecurity guidance is also useful as a reminder that disciplined, repeatable behaviors usually matter more than flashy one-off moments. For a learner, that translates into rubrics that prioritize observation quality, branch selection, and recovery.
| Rubric Area | What to Score | Why It Matters |
|---|---|---|
| Observation | Did you catch and prioritize the right clues? | Prevents shallow scanning theater |
| Hypothesis Quality | Did your next steps follow evidence? | Improves decision-making under uncertainty |
| Documentation | Could you reconstruct the session later? | Makes review and repetition possible |
| Recovery | How well did you pivot after error? | Reflects real operator resilience |
Build the Review Loop: How to Debrief a Kioptrix Session Without Lying to Yourself
Write a short after-action review while the session is still warm
Do not wait until tomorrow if you can help it. Memory edits quickly. The emotional texture fades. The points of confusion flatten. A short after-action review, written while the session is still warm, captures the truth before the brain starts sanding off the rough edges.
Keep it short enough that you will actually do it. Five to ten minutes is plenty. The point is not literary beauty. It is fidelity. You are preserving the state of your thinking before hindsight strolls in wearing a fake badge. If you need a practical starting point, a lightweight Kioptrix lab report format keeps the review loop from dissolving into vague memory.
Name one strength, one miss, one pattern, and one next fix
This four-part structure is powerful because it balances honesty with direction. One strength prevents the review from becoming punitive theater. One miss identifies what failed. One pattern looks for recurrence. One next fix keeps the whole thing actionable. You leave with a target, not just a mood.
For example: strength, “I documented web findings more clearly than last time.” Miss, “I over-trusted a familiar service banner.” Pattern, “I keep pivoting before exhausting the strongest clue.” Next fix, “For the next three sessions, I will write one sentence explaining why I abandoned a branch.” That is a review with bones.
Compare this attempt to your prior attempt, not to someone else’s highlight reel
This matters more than most people admit. Cybersecurity learning online can be weirdly theatrical. Fast solves, clipped videos, triumphant screenshots, timelines that smell slightly fictional. If you compare your messy process to someone else’s highlight reel, you will misread your growth.
Compare across your own sessions instead. Did your notes get clearer? Did your branching improve? Did you recover from confusion faster? Did you need fewer emotional escape hatches? Those are meaningful wins, even if your total time did not collapse dramatically.
- Review while the session is still warm
- Track one strength, one miss, one pattern, one fix
- Compare against your own prior run, not internet theater
Apply in 60 seconds: Create a review template now so your future self has no excuse to “do it later.”
Make It Career-Useful: Turning Self-Assessment Into Interview-Ready Evidence
Employers care about judgment under uncertainty, not just terminal fluency
This is where the whole exercise quietly turns into career capital. Employers do care about technical ability, but they also care about how you think when things are incomplete, noisy, or ambiguous. Can you form a sensible path from partial evidence? Can you recover after a wrong turn? Can you document your reasoning clearly enough that someone else can trust your work? Those questions matter in actual teams.
NIST’s NICE material is helpful here because it frames cybersecurity work as a combination of tasks, knowledge, and skills. That is a useful reminder that your development should not be measured only in exploits landed. Communication, documentation, analytical thinking, and repeatable workflow all count because they all show up on the job.
A good story shows what you noticed, changed, and learned
Interview-ready evidence does not mean narrating every command like a courtroom stenographer. It means building a concise story. Situation: what was the environment? Obstacle: where did uncertainty or friction appear? Action: what did you test and why? Result: what changed? Reflection: what did you learn about your process?
The reflection part is usually the weakest, which is a pity, because it is often the most memorable. Anyone can list tools. Fewer people can say, calmly and clearly, “I realized I was overweighting familiar services and under-documenting my web observations, so I changed my note structure and improved the next run.” That sounds like someone who can learn on purpose. If you want that material to travel well, these Kioptrix interview story patterns are especially useful for turning honest review notes into hiring-language proof.
Your review notes can become proof of maturity and coachability
Good review notes are not just for private growth. They become raw material for interviews, portfolio writeups, study retrospectives, and mentor conversations. They show that you can examine your own work without melodrama. That is maturity. They show that you can identify patterns and act on them. That is coachability.
And frankly, coachability is often underrated by learners who imagine hiring is a pure command contest. It is not. Teams want people who can think, communicate, improve, and avoid turning small uncertainty into large chaos. A person who can describe a missed clue honestly may sound more trustworthy than someone who recites an immaculate but suspiciously frictionless path.
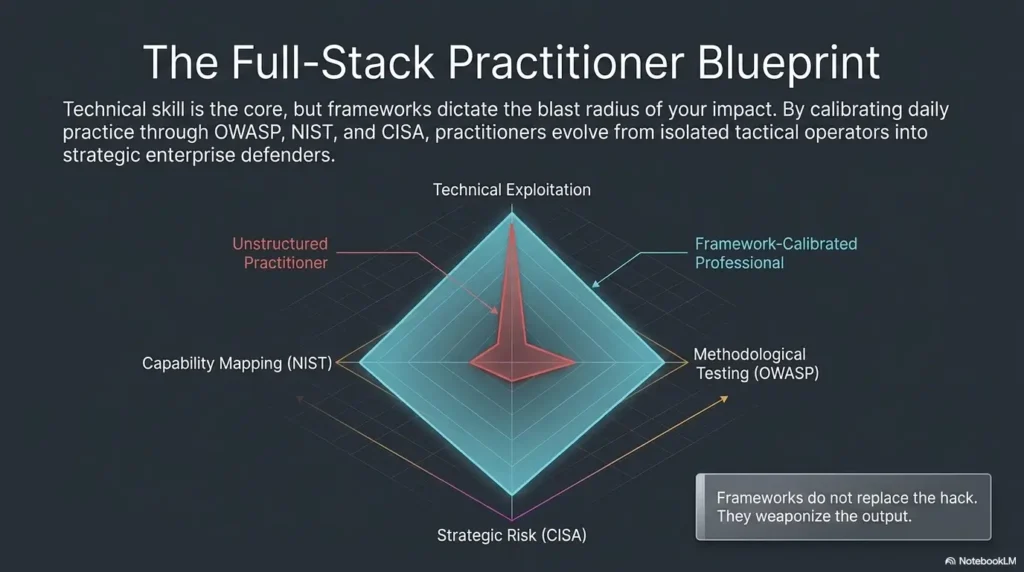
Next Step: Run One Session With a Four-Column Review Sheet
Create columns for Evidence, Assumptions, Decisions, and Misses
If you want one high-leverage next step, this is it. Run your next Kioptrix session with a simple four-column sheet: Evidence, Assumptions, Decisions, Misses. That structure is simple enough to use live and powerful enough to reveal where your process bends. You do not need fancy tooling. A plain text file or notebook is enough.
Evidence records what you directly observed. Assumptions records what feels likely but is not yet proven. Decisions records why you chose a branch. Misses records what you overlooked, misunderstood, or delayed too long. By the end of the session, you will have a much cleaner picture of your technical habits than “I got root in X minutes” could ever provide.
Finish the lab, then review the sheet before reading any solution
This ordering matters. Extract your own learning first. Then review. Then, if needed, consult a solution. That sequence preserves the integrity of the assessment. It lets you compare your independent reasoning with an external path rather than blending the two so early that neither can be evaluated clearly.
A practical rhythm might look like this: 45 to 60 minutes of work, 10 minutes of review, then solution comparison only if necessary. Not glamorous. Very effective. Like good shoes, it does not need fireworks to prove its worth. For readers trying to make this sustainable, a guide on realistic Kioptrix session length can keep the habit from becoming performative.
Use that review to choose the single skill to improve next, not five at once
The final trap is trying to fix everything at once. Resist it. Choose one next skill. Maybe that is better web enumeration notes. Maybe clearer branch labels. Maybe waiting longer before hints. Maybe distinguishing inference from assumption. One targeted improvement per session is sustainable. Five is how good intentions turn into compost.
The curiosity loop from the beginning closes here: Kioptrix helps because it turns an old lab into an honest mirror. Not a perfect mirror. Not a flattering one. But an honest one. And if you can learn to face that kind of mirror without flinching, your technical growth becomes steadier, calmer, and much more real. Readers who want to zoom out from this one box can also use a broader Kioptrix learning path to decide what comes after reflection becomes a habit.
Coverage tier map for your self-review
- Tier 1: I only tracked commands
- Tier 2: I tracked commands and results
- Tier 3: I tracked evidence and branch decisions
- Tier 4: I tracked assumptions, misses, and pivots
- Tier 5: I can compare repeated runs and name a recurring pattern
Neutral next step: Aim to move up just one tier on your next session.
FAQ
Is Kioptrix good for beginners who want to measure real progress?
Yes, especially if the goal is honest progress rather than novelty. The lab is small enough that beginners can inspect their own habits without drowning in complexity. The key is to measure process, not just completion. For readers still deciding whether the box fits their stage, Kioptrix for beginners offers a useful companion angle.
How do I know whether I truly improved or just memorized the box?
Look at your notes and decisions, not only your finish time. If you can explain why each branch made sense from live evidence, label assumptions clearly, and reproduce the path from your own documentation, that is stronger evidence of improvement than simple speed alone.
Should I use walkthroughs when assessing myself?
Yes, but later. First run your own session, record your evidence and decisions, and write a short review. Then compare your work to a walkthrough. Used in that order, a walkthrough becomes a learning amplifier instead of a truth blur.
What should I track during a Kioptrix session?
At minimum, track time, observations, why each clue matters, your current hypothesis, branch decisions, and misses. A four-column sheet for Evidence, Assumptions, Decisions, and Misses is a very practical starting point.
Is speed a useful measure of technical growth?
Sometimes, but only as a secondary metric. Speed can improve for good reasons, such as cleaner observation and better branching. It can also improve for bad reasons, such as memory contamination or premature hint use. Treat it carefully.
Can failed attempts still count as progress?
Absolutely. A failed attempt that reveals a recurring blind spot can be more educational than a lucky success. The important part is whether you document the miss clearly enough to turn it into a future study target.
How often should I repeat the same Kioptrix level?
Repeat it when you want to compare process across runs. The value is not endless repetition for its own sake. The value is controlled comparison. Two or three well-documented runs can tell you much more than one messy win.
What makes a self-assessment note actually useful later?
A useful note preserves sequence, evidence level, and reasoning. It should tell your future self what you observed, what you thought it meant, why you chose a branch, and where the path went wrong or right.
In the end, the promise of this lab is not that it will make you look brilliant by sunset. It is that it will make you more truthful by sunset, which is a sturdier thing. The old machine on the screen becomes a mirror for your pacing, your assumptions, your note quality, your recovery, and your judgment under uncertainty. That is the curiosity loop closed. Kioptrix helps because it makes your technical self visible.
So here is the honest 15-minute next step: open a blank note, make four columns, and run one short session with the sole purpose of labeling evidence, assumptions, decisions, and misses. Do not try to improve everything. Pick one recurring weakness and tighten it. Quiet progress like that does not always feel cinematic. It feels better. It feels real.
Last reviewed: 2026-04.