


Stop Choosing Security Controls Your Team Can’t Operate
Most startups don’t fail because they chose the wrong control. They fail because they chose one they couldn’t sustain by week three. In the WAF vs. RASP vs. CSP debate, the winner is the one that reduces exploitability without hijacking your release cadence.
For lean engineering orgs, the real pain is alert churn, exception chaos, and security work that quietly steals bandwidth from your roadmap.
This guide provides a practical, startup-ready decision path to choose your stack by attack surface, operator time, and deployment friction.
Built for production realities: No vendor theater, just measured outcomes.
Table of Contents

1) Decision first: what are you actually defending this quarter?
The real constraint is not money. It’s security attention
Most startup security conversations pretend the bottleneck is budget. In practice, budget hurts, yes, but attention is scarcer. You can find spend. You can’t mint calm, focused incident responders overnight. I’ve seen a seven-person engineering team buy an advanced control, then quietly disable half of it by week three because nobody had time to tune alerts between release deadlines.
So start here: if your team can dedicate only 3–5 focused hours weekly to app-layer defense, prioritize controls with lower tuning overhead and clear blast-radius reduction. That usually means WAF and a disciplined CSP rollout before anything deeper, then validating those choices through founder-friendly security metrics that track real outcomes.
Threat model snapshot: public web app, API-heavy backend, or both?
If your revenue path is browser-first, script injection and session abuse matter immediately. If you’re API-heavy, auth misuse and business logic abuse dominate post-login risk. If you’re both (most SaaS teams are), you need layered controls, but not all at once.
- Public web + login pages: prioritize edge filtering and browser guardrails.
- API-heavy product: prioritize request normalization, auth analytics, and abuse detection workflows.
- Hybrid SaaS: phase controls to avoid operational collapse.
Pattern interrupt — Let’s be honest: your “security roadmap” is really a staffing roadmap
Write this sentence on a sticky note: “If we can’t run it in production, we don’t own it.” That line saves more money than any vendor discount. The startup trap is buying tomorrow’s control with today’s team. A control that fires 10,000 alerts nobody triages is not protection. It’s theater with logs.
- Define who tunes policies weekly.
- Map controls to top 5 revenue-impact attack paths.
- Reject tools with unclear on-call workflows.
Apply in 60 seconds: Assign one owner per control before approving any purchase.
2) WAF in plain English: fast shield, imperfect visibility
What WAF blocks well (OWASP-style patterns, bot noise, volumetric abuse)
WAF is your front-door bouncer: fast, scalable, and very useful against known-bad request patterns. It shines when traffic spikes, scanners get noisy, and commodity attacks try simple injection payloads. For early teams, that immediate noise reduction is not glamorous, but it buys precious time.
I once watched a product launch weekend go from “Slack on fire” to “mostly normal” after enabling managed WAF baselines plus rate limits. No fireworks. Just fewer distractions and fewer obvious bad requests reaching the app.
Where WAF underperforms (logic abuse, authenticated misuse, deep app context)
WAF struggles where context matters: post-login abuse, role confusion, workflow manipulation, and legitimate-looking calls that are malicious in sequence. If an attacker behaves like a user and abuses business logic, WAF often sees “valid HTTP.”
That does not make WAF weak. It makes it bounded. Treat it as necessary edge hygiene, not a full app-layer detective.
Best-fit startup scenarios: launch week, traffic spikes, compliance pressure
For seed-to-Series B teams, managed WAF often delivers the best 30-day risk reduction per operator hour. It can also support compliance conversations when buyers ask how you protect internet-facing endpoints. Cloudflare, AWS WAF, and Fastly are common options teams evaluate, usually alongside platform-native logging and SIEM sinks.
- Choose WAF first if you need protection in days, not quarters.
- Delay deeper runtime controls if no one can own tuning weekly.
- Add CSP next if your front-end uses dynamic scripts and third-party tags.
Neutral next step: Run a 2-week WAF baseline and measure blocked-to-benign ratio.
Show me the nerdy details
Managed WAF value usually comes from mature managed rule sets, bot controls, IP reputation feeds, and edge rate-limiting. The hard part is exception hygiene: endpoint-level allowlists, payload size tuning, and avoiding broad bypass patterns that silently re-open risk.
3) RASP under the microscope: deeper context, heavier operations
Why RASP sees what edge controls miss
RASP runs close to code execution, so it can observe runtime behavior that edge tools cannot: suspicious method calls, unsafe deserialization patterns, and exploit attempts disguised as normal requests. In the right app, this is powerful. Especially when an attack only becomes obvious inside the runtime.
In one pilot I advised, RASP surfaced an abuse path that looked “clean” at the edge but turned nasty after a specific object lifecycle. That visibility mattered. It also created new work.
Tuning burden and false-positive fatigue in lean teams
RASP can generate deep insights and deep fatigue. Every sprint changes code paths. Every change can alter runtime behavior and policy outcomes. If your team lacks AppSec depth, you risk alert churn and quiet quitting by dashboard.
This is why RASP is rarely the first control for lean teams. Not because it is bad. Because it asks for operational maturity many startups don’t yet have.
Open loop — The hidden question: can your team own runtime policies every sprint?
If the answer is “not yet,” run a scoped pilot on one critical service with strict exit criteria. Example: continue only if false-positive triage stays under a fixed weekly hour budget and incident signal quality improves measurably.
- Pilot one service before broad rollout.
- Set a hard weekly triage budget.
- Define kill-switch conditions in advance.
Apply in 60 seconds: Write a one-line RASP exit rule: “Stop pilot if triage exceeds X hours/week for 2 weeks.”
4) CSP as damage control: browser-enforced guardrails, if you do it right
What CSP can prevent (script injection blast radius, data exfil paths)
CSP is often misunderstood as a silver bullet. It is not. It is a browser-side policy framework that limits where scripts, frames, and other resources can load from. Done well, it reduces script-injection impact and constrains exfiltration paths. Done lazily, it’s decorative HTML jewelry.
When teams move from permissive wildcards to nonce/hash-based directives, risk compresses. Not vanishes. Compresses.
Rollout reality: report-only mode, policy tightening, breakage testing
Safe CSP rollout is a lifecycle practice:
- Start in Report-Only mode.
- Inventory inline scripts and third-party tags.
- Tighten directives in controlled steps.
- Test critical flows before enforcement.
For React/Next.js teams, the friction usually comes from legacy inline snippets, analytics tags, and marketing scripts added “just for this campaign.” I’ve seen one tiny marketing pixel delay CSP enforcement by two sprints. Real life is messy.
If script sprawl is already visible in cloud assets, pair CSP work with a quick pass on common cloud misconfiguration patterns that widen exposure.
Inputs (0–2 each):
- Inline script count known? (0 no / 1 partial / 2 yes)
- Third-party script owners assigned? (0 no / 1 partial / 2 yes)
- Critical user flows tested with CSP report-only? (0 no / 1 some / 2 yes)
Score: 0–2 = not ready, 3–4 = pilot now, 5–6 = enforce in phases.
Neutral next step: If score ≤4, keep Report-Only and close one gap this week.
5) Cost reality check: license price vs operational complexity
Direct cost buckets (tooling, traffic, premium features, support tiers)
Startups often compare line items and miss the expensive part: interruptions. Yes, there are direct costs such as per-request pricing, feature tiers, managed support, and enterprise add-ons. But the larger cost in year one is usually context switching: engineers breaking sprint focus to chase noisy signals.
Hidden costs (engineering interruptions, alert triage, policy maintenance)
Hidden costs are predictable:
- Emergency exemptions during launches.
- After-hours triage with unclear ownership.
- Policy drift as teams ship fast.
- Unplanned effort to normalize logs and dashboards.
I once watched a team save 30% on license spend and lose 2 release cycles to ad-hoc tuning. On paper: savings. In reality: negative ROI. That exact blind spot is why security controls should be framed as revenue and reliability decisions, not checkbox purchases.
TCO lens: 90-day cost-to-value, not annual sticker price
Use a 90-day lens. Ask: “What can we deploy, tune, and operationalize this quarter with current staffing?” The best control is the one that lowers real incident likelihood and survives your release cadence.
| Control | Typical Year-1 Spend Shape | Ops Load | Notes |
|---|---|---|---|
| WAF | Low-to-medium, traffic-sensitive | Low-to-medium | Fastest time-to-value for most startups. |
| CSP | Low tooling, medium engineering time | Medium | High payoff if maintained as practice, not one-off. |
| RASP | Medium-to-high | Medium-to-high | Best for teams that can sustain runtime policy ownership. |
Neutral next step: Estimate 90-day engineering interruption cost before approving vendor spend.
6) Common mistakes startups repeat (and pay for later)
Buying RASP before basic edge hygiene is stable
If WAF baselines are noisy and auth telemetry is thin, adding runtime controls can amplify confusion. It’s like upgrading to racing tires while your brake pads are worn.
Treating CSP as a one-time header instead of a lifecycle practice
CSP is not set-and-forget. Every new third-party script, tag manager change, and inline snippet can erode policy quality. Mature teams revisit directives as part of release hygiene.
Confusing “fewer alerts” with “lower risk”
Fewer alerts can mean better tuning or blind spots. Signal quality beats silence. If alert volume drops but suspicious conversion anomalies or account abuse rise, your system may be quieter and weaker.
7) Who this is for / not for
This is for: seed-to-Series B teams running internet-facing apps with limited SecOps depth
If your team ships quickly, owns production directly, and has no 24/7 SOC, this framework fits. It assumes limited analyst bandwidth and frequent product change.
Not for: mature enterprises with dedicated AppSec + 24/7 SOC
If you already run dedicated AppSec engineering, threat hunting, and mature detection pipelines, your control order may differ. You can absorb higher operational complexity earlier.
If you outsource security: what to keep in-house anyway (ownership boundaries)
Outsourcing helps, but you still need internal ownership for risk acceptance decisions, exception approvals, incident severity definitions, and release gating criteria.
8) Architecture fit: choose by app shape, not hype
Monolith + limited release cadence: likely WAF + CSP baseline
Monoliths with predictable release windows can benefit quickly from WAF at the edge and CSP in the browser.
Microservices + frequent deploys: where RASP might earn its keep
In fast-moving microservices environments, runtime visibility can catch edge-missed behavior, but only if your instrumentation and ownership are mature enough to avoid alert fatigue.
API-first products: why WAF rules alone won’t solve auth/business-logic abuse
API abuse often happens after authentication, inside valid request shapes. You need tighter auth telemetry, behavioral baselines, and workflow-aware detection beyond simple signature blocking. A lightweight starting point is to run MVP threat modeling for startup attack paths before choosing tool depth.
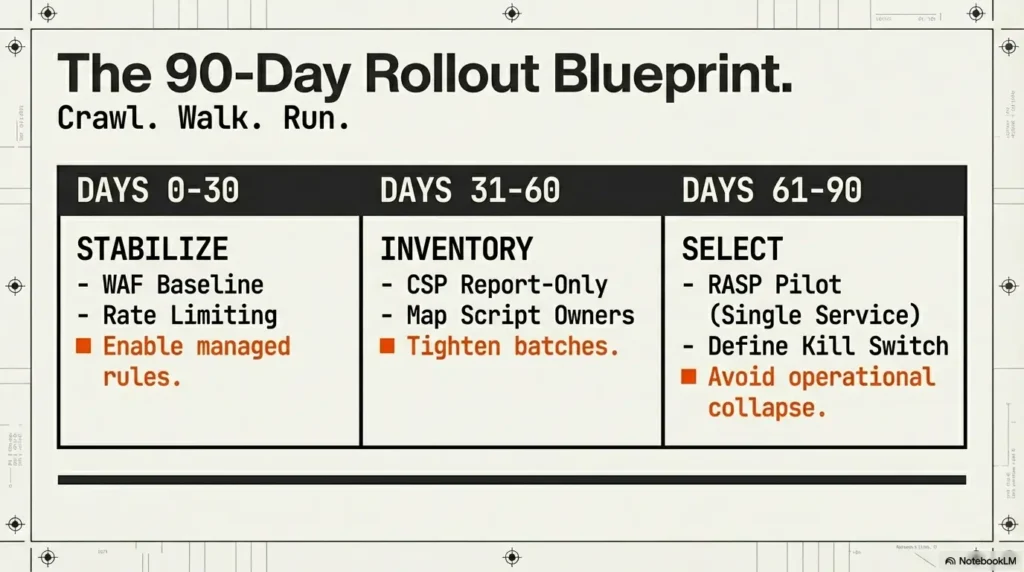
9) Phased rollout blueprint (30/60/90 days)
First 30 days: WAF baseline rules, logging hygiene, incident thresholds
Week 1: enable managed baselines and sane rate limits on internet-facing routes.
Week 2: define exception process (who approves, how long exceptions live).
Week 3: standardize log fields and incident tags.
Week 4: set response thresholds and escalation paths.
Days 31–60: CSP report-only, inventory inline scripts, tighten directives
Run report-only mode and collect violation data. Build a script owner map across product, marketing, and analytics. Tighten in batches by route criticality.
Days 61–90: RASP pilot on one critical service, success/failure exit criteria
Pick one service with clear risk and clear owner. Continue only if signal improves without creating unacceptable release friction.
10) Metrics that matter: prove security value without vanity charts
Mean time to detect/respond for app-layer incidents
Track detection and response times for real app-layer events. If controls are working, response should get faster and less chaotic over time.
Blocked-to-benign ratio (signal quality over alert volume)
A high alert count is not a trophy. Track what fraction of blocked events are genuinely suspicious after triage.
Release friction index: how much security slows shipping
Measure deployment delays and hotfix churn attributable to security controls. If protection increases but release reliability collapses, leadership deserves to see that trade-off clearly. You can operationalize this with clear vulnerability remediation SLAs tied to business risk.
- Track incident speed, not alert volume alone.
- Map metrics to top breach paths quarterly.
- Include release friction in security reviews.
Apply in 60 seconds: Add one line to monthly reporting: “Which top attack path got harder this month?”
FAQ
Is WAF enough for a startup SaaS product?
Usually not by itself, but it is often the best first layer. WAF handles edge-level noise and common web attack patterns well. You still need strong auth hygiene, logging, and browser-side hardening like CSP where relevant.
Does RASP replace WAF, or do I need both?
RASP does not replace WAF in most startup environments. WAF protects the edge broadly with lower operational burden. RASP can add deep runtime visibility for specific services if your team can own tuning and response.
Can CSP stop all XSS attacks?
No. CSP can significantly reduce exploitability and blast radius when policies are strict and maintained. But it is not a guarantee against all XSS variants.
Which is cheapest in year one: WAF, RASP, or CSP?
For most small teams, managed WAF plus disciplined CSP rollout tends to deliver better year-one cost-to-value than immediate broad RASP rollout.
What KPIs should founders ask for in monthly security reviews?
Ask for app-layer detection/response time, blocked-to-benign ratio, release friction index, and one concrete breach-path hardening update.
12) Next step: one concrete action
Run a 45-minute control fit workshop this week
Invite engineering, product, and whoever owns incident response. Keep the room small, honest, and decision-focused.
Output required: app inventory, top 5 attack paths, 90-day phased choice (WAF/CSP/RASP)
Use one page. No slide deck. If it spills into 20 pages, you’re avoiding the decision. If customer due diligence is active this quarter, pair the workshop outcome with a vendor security questionnaire response pack so security decisions and sales evidence stay aligned.
Decision rule: pick the control your current team can operate reliably in production
Close the loop from the opening: you’re not buying security comfort. You’re building an operating system for risk decisions under pressure. The best stack for most startups right now is still: WAF first, CSP second, RASP selectively. If your team can run that reliably for 90 days, you’re ahead of most peers without burning the roadmap.
- Monthly request volume and peak traffic profile
- Critical routes and auth-sensitive endpoints
- Current logging stack and retention window
- On-call ownership model and escalation path
- Acceptable weekly tuning time budget
Neutral next step: Send this list with every RFP so quotes are comparable.
Last reviewed: 2026-02.