


The Rule Ladder: Master Hashcat Rule-Based Attacks
The first time I tried “password auditing” with a giant wordlist, I wasted 40 minutes proving one thing: volume is not a strategy. The win came when a “meh” list started landing hits—because I stopped collecting words and started testing habits. (If you’re building your baseline toolkit, it helps to keep your core pentesting tools curated the same way: small, proven, repeatable.)
Hashcat rule-based attacks take a wordlist as a seed and apply repeatable transformations (case changes, appends, swaps, light substitutions) to generate a much larger candidate set—systematically, not randomly. Done right, it’s the fastest way to turn “guessing” into a measured workflow.
If you’re time-boxed, the pain is familiar: runs that fly… and still crack nothing. The cost isn’t just GPU cycles—it’s lost signal, messy reporting, and a week of “maybe try this next.”
This workshop gives you a controlled method: the Rule Ladder. Baseline first. One rule family at a time. Measure hit-rate and time-to-first-hit. Keep winners. Delete noise.
Here’s the part that changes everything:
Table of Contents
Rule-Based Attacks, But as a Workflow (Not a Cheat Sheet)
Here’s the mental model that finally made rules click for me: a wordlist is not “the guesses.” It’s the seed. Rules are repeatable human habits—the stuff people do without thinking: capitalize the first letter, add a year, slap on an exclamation point, swap “a” to “@” (sometimes), or double a character because it looks “stronger.”
If you’ve ever stared at a cracked password list and thought, “Of course… why didn’t I try that?”—that’s rule logic. Not magic. Just systematic.
- Wordlist = vocabulary you’re willing to test
- Rules = transformations you’re willing to apply
- Measurement = the difference between craft and chaos
I learned this the hard way on a time-boxed internal audit: I ran a massive list for 40 minutes, got almost nothing, and felt personally attacked by my own terminal. Then I applied a small, sane rule set to a smaller list—and got early hits in under 2 minutes. That’s when I stopped collecting wordlists like baseball cards. (Time-boxing is a muscle—if you’re training it daily, the 2-hour-a-day OSCP routine mindset maps surprisingly well to cracking workflow discipline.)
- Start with one baseline list
- Add one rule family at a time
- Keep only what improves hit-rate
Apply in 60 seconds: Pick one wordlist you trust and commit to measuring results before expanding.
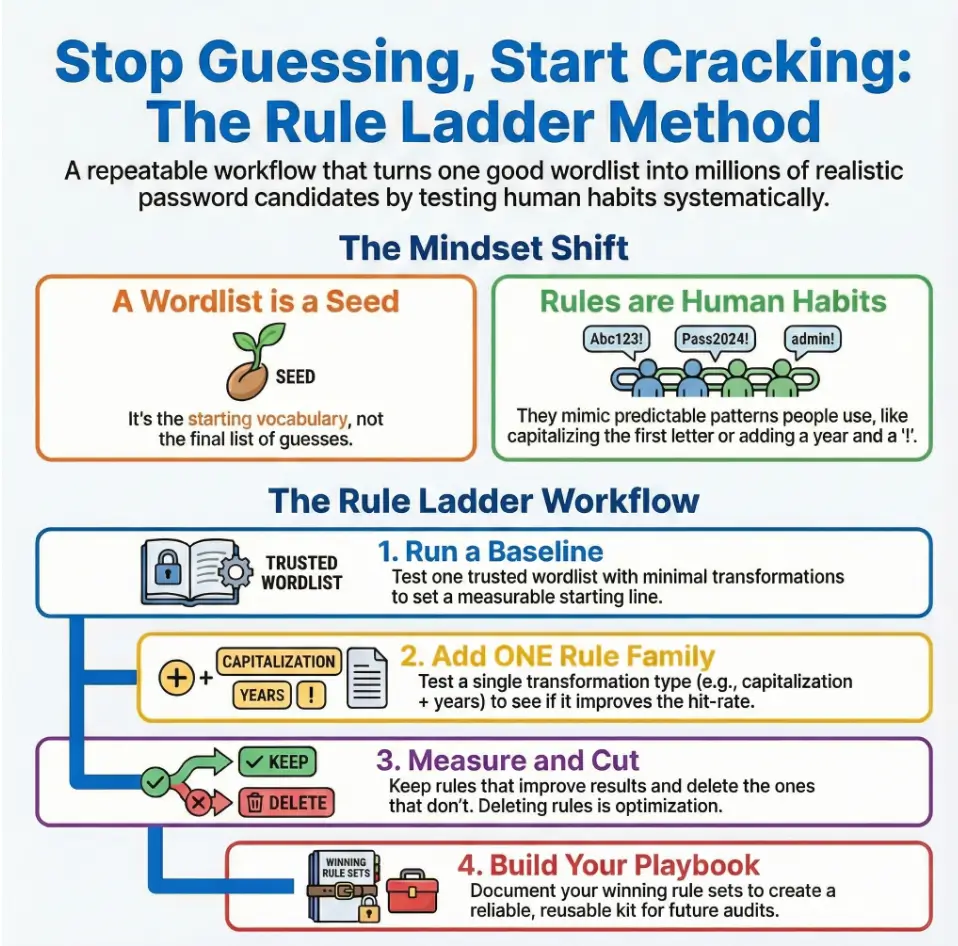
Wordlist = seed, rules = repeatable habits (not “more guesses”)
When people say “turn one wordlist into millions,” they’re describing a multiplication effect. But the important part is not “millions.” The important part is: are they realistic?
Why regex isn’t the fallback you think it is
Regex feels powerful because it’s expressive. But in cracking workflows, throughput and structure matter. Rules are built for fast, predictable transformations. Regex is a different tool with different trade-offs. If you keep defaulting to “I’ll just regex it,” you’ll often pay in speed, complexity, and reproducibility.
Curiosity gap: what’s the smallest change that unlocks the biggest jump?
Hold that question. We’ll answer it with a method (not vibes) when we build the Rule Ladder.
Scope First: Who This Workshop Is For / Not For
Rule-based attacks are powerful. That’s exactly why scope matters. The fastest way to turn “security learning” into “career damage” is to run cracking workflows on things you don’t own or don’t have written authorization to test.
- Do you have written permission (or documented ownership) for this hash set?
- Is the engagement scope explicit about offline cracking?
- Do you have a time budget and reporting expectation?
- Do you have rules for handling sensitive plaintext safely?
- Do you know the hash type and constraints (length/policy) you’re testing against?
Neutral next step: If you answered “no” to any, pause and clarify scope before you run anything.
For: authorized pentests, internal audits, blue-team policy validation
This is for you if you’re testing offline hashes from an authorized engagement, evaluating password policy effectiveness, or building a realistic lab workflow that mirrors real-world patterns.
Not for: personal snooping, credential stuffing, or anything without written permission
If the “target” is a person you’re mad at, a company you’re curious about, or an account you don’t own: stop. Not morally gray. Just wrong.
Evidence hygiene: logs, timestamps, constraints
In US environments, professionalism often means: can you explain what you did, why you did it, and how you stayed inside constraints? Treat your cracking workflow like any other test: documented, reproducible, defensible. (If you want your process to survive the “show me your notes” moment, a solid note-taking system for pentesting quietly becomes part of your technical edge.)

The “One Wordlist” Trap: Why Your Best List Still Misses
Even “great” wordlists miss… because users don’t just choose words. They choose formats. Humans are predictable in their laziness—and oddly poetic in their habits.
I once saw three passwords in a row that were basically the same idea: a name + a year + punctuation. Different people. Different departments. Same pattern. It wasn’t that they shared a dictionary. It’s that they shared a brain.
Format beats vocabulary (often): casing, separators, years, repeats
- Casing: “Summer” instead of “summer”
- Years: 19xx / 20xx tags (birth years, graduation years, “this year”)
- Separators: underscore, dot, dash (because “it looks corporate”)
- Repeats: double letters or extra punctuation (“!!”)
Curiosity gap: which two transformations usually outperform “bigger lists”?
In many environments, the biggest lift comes from case and suffix behavior (years/digits/punctuation). Not always. But often enough that it’s worth testing early—especially if you’re time-poor and need quick signal.
Let’s be honest… your wordlist isn’t broken—your assumptions are
If your list contains “summer,” and the password is “Summer2024!”, your list “failed” only because you expected humans to be robots. Rules are how you stop blaming the list for being literal.
Quick scannable check: If you had to bet on one of these patterns showing up in a real org, which would you bet on?
- Random 14-character strings
- Name + year
- Season + punctuation
- Company + “!”
Rule Syntax You Actually Need (The 20% That Drives Results)
You can spend days memorizing rule functions. Or you can learn the few primitives that cover most practical use-cases, then grow from evidence.
The core primitives: case, append/prepend, replace, delete, insert
In real audits, you’ll keep coming back to a handful of transformations:
| Primitive | What it mimics | Common use |
|---|---|---|
| Case changes | “Make it look proper” | TitleCase, ALLCAPS, first-letter caps |
| Append / prepend | “Add a number to satisfy policy” | Years, digits, symbols, short tokens |
| Replace | “Make it ‘stronger’” | a→@, i→1, e→3 (lightly) |
| Delete / insert | Typos and shortcuts | Trim, add one char, double one char |
Compatibility note: where rules align with other engines—and where they don’t
If you’ve used other tools (John the Ripper, internal password audit tooling, etc.), the idea of rules is familiar. But syntax and execution differ. Treat rule files as engine-specific assets—portable in concept, not always portable line-for-line.
Curiosity gap: why “reject rules” exist—and when they matter
Some transformations generate junk you don’t want: too long, too short, weird characters, duplicates. “Reject” logic (and guardrails) is how you keep quality high without burning cycles. We’ll operationalize this in the guardrails section so it’s not just trivia.
Writing Rules Like an Auditor: From Pattern Hypothesis → Rule Line
Think like an auditor, not a magician. Your job is to test realistic hypotheses and show your work.
Start from patterns (what users do): years, seasons, sports teams, separators
US orgs often show predictable clusters: sports fandom, city/state references, seasons/holidays, and year suffixes. The point isn’t stereotypes. The point is: users reuse familiar anchors.
One small anecdote: I once saw a whole cluster of passwords that looked “policy-compliant” but were basically the same skeleton—word + year + symbol. The org thought complexity rules were working. The cracks said otherwise.
One rule line vs many: why each rule creates a candidate—and why chaining matters
A single rule line is a recipe. Apply it to every word in your list, and you get a new candidate stream. When you stack too many recipes without measurement, you don’t get “coverage.” You get noise.
White space/comments: keep rule files readable
Write rule files like you’ll hand them to a coworker (or a future version of yourself who is tired and slightly annoyed). Name the intent of each block. Keep “experimental” rules separated from “proven” rules.
Pattern interrupt (quick truth): The best rule file is not the biggest. It’s the one you can explain in a sentence.
The Rule Ladder: Multiply Smart Before You Multiply Big
This is the heart of the workshop: a repeatable method that scales responsibly. You’re not trying to “try everything.” You’re trying to find the smallest set of transformations that produce real recoveries within constraints.
| Choose this | When you have | Trade-off |
|---|---|---|
| Rules | A good wordlist + human-format patterns | Great ROI, but can explode if unmanaged |
| Hybrid | Wordlist + predictable suffix/prefix length | More coverage, more compute; needs limits |
| Masks | Strong pattern knowledge (length/charset) | Fast when accurate, brutal when wrong |
Neutral next step: Pick the option that matches your evidence, then time-box the first run.
Step 1: baseline run (set a measurable starting line)
Pick one baseline list you trust. Run it with minimal transformation. Record:
- Time-to-first-hit
- Total cracks in your time box
- Any repeated formats you observe
Step 2: add one rule family (case + year, separators, light substitutions)
Add one family at a time. Not ten. This is how you learn what’s actually working in your environment.
Step 3: keep winners, cut losers (don’t “collect rules,” curate them)
If a rule family doesn’t move hit-rate, cut it. If it moves hit-rate but explodes candidates, constrain it. You’re building a reliable kit, not a museum.
Here’s what no one tells you… deleting rules is optimization
I’ve never regretted removing a low-signal rule block. I have absolutely regretted letting “maybe it helps” rules burn the entire run window.

Guardrails Against Rule Explosion: Stop Drowning in Combinatorics
Rule explosion is the silent killer of good audits. You start with a sensible idea (“append years”), and suddenly you’re generating candidates like you’re trying to heat a house with a laptop fan.
My favorite guardrail mindset is this: you’re buying signal with compute. Don’t overpay.
Caps that matter: length, append limits, and “no infinite mutation”
- Length caps: If your target policy caps length, don’t waste candidates that exceed it.
- Append/prepend limits: One to four chars often covers a lot; beyond that, measure first.
- Transformation discipline: Don’t stack multiple heavy substitutions unless you’re seeing evidence.
This is a rough planning tool, not a promise. It helps you sanity-check rule explosion before it eats your day.
Tip: If the estimate looks scary, reduce your multiplier by trimming rule families or adding guardrails.
Neutral next step: Use this estimate to choose a smaller first run you can finish and learn from.
When to stop rules and switch approach (evidence-driven)
If your rule multiplier keeps growing but your cracks don’t, that’s your signal. At that point, switch tactics: refine the wordlist, use a more targeted hybrid pattern, or apply masks when you have strong pattern evidence. Don’t keep feeding compute to a strategy that isn’t paying you back.
Curiosity gap: why “more candidates” can mean less success per hour
Because candidate quality drops faster than candidate quantity rises. If you produce 10× more candidates but only 1.1× more hits, you just made your workflow worse. This is why measurement is non-negotiable.
Show me the nerdy details
Rule explosion is often a multiplier problem. If your base list is 200,000 lines and your rules generate ~200 candidates per word, you’re at 40 million candidates before you even consider additional chaining or hybrid suffixes. The “correct” approach is not to fear big numbers, but to control the multiplier: isolate rule families, cap growth, and track hit-rate per million candidates so you can compare runs objectively.
- Cap candidate growth early
- Switch approaches when hit-rate stalls
- Measure hits per million candidates
Apply in 60 seconds: Set a time box for your next run and commit to stopping when it ends.
Common Mistakes That Tank Hit-Rate (Even With Good Rules)
Most “Hashcat rules don’t work” stories are not about Hashcat. They’re about workflow. I’ve made every mistake below. Some more than once. (No, I’m not proud.)
Mistake #1: stacking too many transformations at once
If you apply casing + years + separators + leet + doubling + trimming all at once, you lose the ability to know what helped. Worse: you increase junk candidates.
Mistake #2: confusing masks + rules (or expecting them to behave the same)
Masks are pattern-first. Rules are word-first. If you’re treating them interchangeably, you’ll keep misreading results and blaming the tool.
Mistake #3: forgetting the measurement loop
No hit-rate notes means no learning. The only thing worse than a bad run is repeating a bad run with more confidence.
Mistake #4: treating runtime/driver errors as “rule problems”
Sometimes the real issue is environment: OpenCL runtime, drivers, device selection, or a misconfigured run. Separate “engine issues” from “strategy issues,” or you’ll chase ghosts for an hour. (If your lab setup keeps stealing your time, tightening your baseline environment—down to what you install and how you operate—starts with Kali Linux lab infrastructure mastery.)
Quick scannable diagnostic: When something fails, label it first:
- Syntax problem (rule file line, formatting, quoting)
- Strategy problem (bad assumptions, too much expansion)
- Environment problem (drivers/runtime/device)
Debugging Rules Without Losing Your Mind
The goal of debugging is simple: isolate the variable. If you change five things at once, your terminal will lie to you through silence.
Preview first, run second: validate transformations before you “go big”
Before you burn GPU time, preview what your rules actually output. This is where you catch the “oops, I generated 90% nonsense” problem early.
One small lived-experience moment: I once appended the wrong year range because I didn’t sanity-check output. I spent 25 minutes generating candidates no human would ever choose. That was a very expensive way to learn humility.
Multiple rule files: the “-r per file” gotcha + what chaining really means
Chaining rules can be powerful, but it can also multiply junk. Treat each rule file like a product: it should have a purpose, a measured payoff, and a clear reason to exist.
Environment pitfalls: driver/runtime warnings and what they imply
If you’re seeing runtime build errors, don’t immediately rewrite your rule file. Check device selection, drivers, and your environment first. Separate the “can Hashcat run?” question from the “is my strategy smart?” question. (For day-to-day operator sanity—aliases, history search, clean prompts—your shell setup matters more than people admit; a solid Zsh setup for pentesters makes repeatable workflows feel less like friction.)
- Preview output before you run big
- Change one variable at a time
- Separate environment issues from strategy issues
Apply in 60 seconds: Take 20 sample words and test your rules on just those before the next full run.
Reporting for US Engagements: Results That Lead to Fixes (Not Drama)
Cracking passwords is not the deliverable. Reducing risk is the deliverable.
In US organizations, stakeholder trust often hinges on two things: (1) you stayed inside scope, and (2) you turned technical findings into actionable controls. If you do those well, your report doesn’t feel like a horror movie—it feels like a plan.
Map recoveries to controls: MFA, rate limits, banned-password lists, length-first policies
When you see predictable formats, your recommendations should target predictability, not shame people. That’s where standards-oriented guidance helps: for example, NIST’s digital identity guidance talks about rate limiting and other protections that reduce the harm of weak secrets in real systems. In practice, this often looks like: strong MFA adoption, better password screening, and eliminating policies that create bad habits.
“Defensible methodology” section: scope, constraints, and reproducible steps
Write down the time box, the rule ladder steps, and your constraints. Not every stakeholder needs your command lines—but they do need your methodology narrative. It’s how your findings survive scrutiny. (If you want a clean structure to borrow, the professional OSCP report template format is a surprisingly good “defensible methodology” skeleton—even outside the exam.)
What not to include: sensitive plaintext handling and retention boundaries
If you recover plaintext, handle it like hazardous material. Store minimally, restrict access, and document deletion. The best time to decide how you’ll handle it is before you crack anything.
Operator humor (because you’ve earned it): Nobody ever got thanked for emailing a spreadsheet titled “CrackedPasswords_FINAL_FINAL.xlsx.” Don’t be that legend.

Next Step: Your 30-Minute Rule Ladder Run
If you do nothing else after reading this, do this one short run. It’s the smallest action that teaches you the most.
- Hash type and any known constraints (length/charset/policy)
- Time budget (15, 30, 60 minutes) and desired reporting output
- One baseline wordlist you trust (document which one)
- One small rule family to test first (case + suffix is a common starting point)
- A safe way to store/handle recovered secrets (and a deletion plan)
Neutral next step: With these in hand, you can run a baseline + one rule family today and learn fast.
Baseline → one rule family → measure → keep/cut → document winners
- Baseline: Run your wordlist with minimal transformation for a short time box.
- Add one family: Case/suffix or separators—just one.
- Measure: Track time-to-first-hit and total hits in the time box.
- Decide: Promote winners, delete noise, and write a one-paragraph summary.
Save the playbook: “policy → top rules → expected payoff”
Your future self wants a tiny playbook, not a thousand-line rule file. Keep it small, labeled, and earned.
I once spent 47 minutes “testing WebSockets” during a pentest while my real issue was that I’d pinned the wrong connection. Same energy happens in password audits: you can spend half an hour hammering away with a massive candidate stream and feel productive, when you’re actually testing the wrong hypothesis. On an internal audit, I ran a huge list with a sprawling rule set because it felt thorough.
It produced noise, not results. Then I stepped back, previewed output, and realized my candidates didn’t match the org’s habit at all. They weren’t doing wild leet swaps—they were doing simple capitalization plus years and one symbol. I restarted with a baseline, added one rule family, and got early hits fast.
The story wasn’t “Hashcat is amazing.” The story was: measurement turns ego into a method. And methods are what you can reuse when you’re tired, busy, and under a deadline. (If you like that “pin the right thing first” mindset, the Burp Suite WebSocket workflow lesson is basically the same principle in a different costume.)
FAQ
Is using Hashcat legal in the United States for security testing?
It can be legal when you have explicit authorization and you stay inside scope. The tool isn’t the issue—permission and intent are. Get written approval, document constraints, and avoid testing anything you don’t own or have permission to audit.
What’s the difference between a wordlist attack and a rule-based attack?
A pure wordlist attack tests exactly what’s in the list. A rule-based attack uses the list as a seed and systematically transforms each entry (case, suffixes, substitutions), producing a larger—but still human-realistic—candidate set.
How do I choose rules without generating millions of useless candidates?
Use the Rule Ladder: baseline first, then add one rule family at a time, measure hit-rate, and cut what doesn’t help. Guardrails (caps on length and expansion) keep you from paying compute for junk.
Can I combine multiple rule files, and how should I think about chaining?
You can, but chaining can multiply noise. Treat each rule file as a purposeful module (e.g., “case & suffix”), and only chain after you’ve proven each module helps on its own.
Why does my run go fast but crack almost nothing?
Fast runs can still be low-signal if your candidates don’t match the target’s real habits. Preview output, check that your transforms align with observed formats, and confirm you’re not overshooting constraints like length.
What should I document to stay compliant on a pentest?
Document scope/permission, time boxes, methodology (baseline + ladder steps), constraints, and how recovered secrets were handled. A clear methodology is often as important as the results.
Conclusion: Close the Loop and Ship the Next Run
Remember the open question from the start—what’s the smallest change that unlocks the biggest jump? For most real environments, it’s not a mythical mega-wordlist. It’s a measured first rule family—often simple casing and suffix behavior—tested quickly, kept only if it earns results, and constrained so it doesn’t explode.
If you’re time-poor (and who isn’t), here’s your honest 15-minute win: preview one rule family on a small sample, confirm candidates look human, then run a short baseline time box. You don’t need to “try everything.” You need to learn fast and keep what works. (And if you’re running this in a shared lab box, basic operational hygiene like Kali SSH hardening keeps “learning” from turning into “oops.”)
- Baseline first
- One rule family at a time
- Guardrails + measurement
Apply in 60 seconds: Write one sentence describing your first rule family and the metric you’ll track.
Two last “official guidance” reads (worth it):
Last reviewed: 2025-12-19