


Stop Managing Dashboards.
Start Closing Attacker Paths.
Most teams don’t fail vulnerability remediation because they chose 30/60/90—they fail because their SLA says one thing while real-world triage, change windows, and exploit pressure say another.
The pain isn’t “too many findings.” It’s conflicting urgency models—security says exploitability, ops says maintenance windows, and compliance says policy text.
Meanwhile, internet-facing exposure doesn’t wait for meeting cadence. Keep guessing, and you don’t just miss dates—you keep attacker paths open while reporting “on-time” closure.
“A vulnerability remediation SLA is a documented time-bound policy that defines how quickly security findings must be remediated—or formally exceptioned—based on risk, exposure, and business impact.”
This guide helps you set fix timelines that hold up under pressure. You’ll get a practical baseline built from field-tested operating patterns:
- CVSS Context
- KEV Overrides
- Clock Logic
- Audit Scrutiny
Here’s where it gets useful. No fluff. Just a policy your team can execute next sprint.
- Set deadlines by severity and exploitability.
- Define clock start/stop logic in writing.
- Require closure evidence before ticket resolution.
Apply in 60 seconds: Write one sentence: “Criticals on internet-facing assets with active exploitation follow emergency windows, not standard windows.”
Table of Contents

Why “How Many Days to Fix” Is Harder Than It Looks
The real decision: calendar days, business days, or risk days?
Most teams argue about numbers first: 7, 15, 30, 60, 90. But the first real decision is the time model. Calendar days create clarity and urgency. Business days feel “fair” to operations teams with change windows. Risk days—faster clocks for exposed assets, slower clocks for low-impact internals—mirror reality better but demand stronger governance.
In one program I helped stabilize, the policy said “High in 30 days,” but nobody noticed that patch windows occurred every 28–35 days. By the time approvals landed, teams were mathematically late before they started. The number was fine; the workflow was fiction.
What auditors hear vs what attackers exploit
Auditors ask, “Did you meet your policy?” Attackers ask, “Can I chain this path today?” Those are not the same question. If your SLA favors neat percentages over attack-path reduction, you can look compliant and still stay exposed. That is the uncomfortable truth many mature teams eventually face.
Let’s be honest… your scanner score is not your SLA
Scanner severity is input, not verdict. A CVSS 8.8 buried behind hard segmentation is different from a CVSS 7.5 on an internet-facing VPN gateway with stolen credentials in circulation. Your SLA should reflect exploitability, exposure, and business impact—not just default scanner labels.
Decision Card: Which clock model fits your environment?
- Calendar days: Best for contractual clarity; hardest operationally.
- Business days: Best for internal IT alignment; weaker for external commitments.
- Risk days: Best for real risk reduction; needs mature triage discipline.
Neutral next step: Pick one default clock and list only two approved exceptions.
Show me the nerdy details
If you use multiple clocks, document precedence logic: contractual SLA overrides policy SLA; emergency override supersedes standard windows; pause states require ticketed approval and expiry. Without precedence logic, dashboards overcount “on-time” closures while incident risk remains unchanged.
SLA Baseline Matrix: Start Here, Then Tune
Severity-to-deadline starter table (Critical/High/Medium/Low)
Here is a practical baseline that works for many US B2B programs before tuning by asset class. It balances urgency and operational realism:
| Severity | Starter Deadline | Typical Rule |
|---|---|---|
| Critical | 7–15 days | Emergency change path if externally exposed |
| High | 30 days | Standard change unless exploit override applies |
| Medium | 60–90 days | Batch in scheduled maintenance windows |
| Low | 120+ days | Backlog hygiene with periodic review |
Add exploitability tiers (Known Exploited, PoC available, theoretical only)
Then add a second axis: exploitability. If vulnerability intelligence indicates active exploitation, tighten the window regardless of base severity. If there is a public proof-of-concept and broad exposure, shrink timelines by one band. If exploitability is theoretical and exposure is constrained, standard windows can apply with documentation.
Internet-facing vs internal-only: same severity, different clock
Internet-facing findings deserve stricter deadlines. Same CVSS, different exposure. This single rule closes a surprising amount of debate. A junior analyst should be able to look at one ticket and know which clock applies.
- Use a two-axis matrix: severity + exploitability.
- Apply stricter windows to internet-facing assets.
- Document one-line override rules to prevent debate loops.
Apply in 60 seconds: Add one field to your ticket template: “Exposure class: Internet-facing / Internal / Isolated.”
Eligibility Checklist: Does this vuln qualify for emergency window?
- Known exploited by threat intel source? Yes/No
- Internet-facing service or remote access path? Yes/No
- Crown-jewel asset or regulated data path? Yes/No
If 2+ are “Yes,” move to emergency SLA.
Neutral next step: Route qualifying tickets to a same-day triage queue.

The Clock Starts When, Exactly?
Detection time vs triage-complete time vs ticket-created time
This is where strong programs separate from chaotic ones. Pick one start trigger and publish it. My preference for defensibility is ticket-created time with an internal service-level target for triage completion (for example, triage within 1 business day for Critical/High). Why? Detection feeds can be noisy, and delaying ticket creation is visible and governable.
I once watched a team shave apparent MTTR by delaying ticket creation until “triage confidence” was high. Their dashboard looked healthier; their risk did not. When a customer asked for evidence, the timeline looked selective. Not fun.
Paused clocks for approved exceptions (and when pauses are abuse)
Clock pauses can be legitimate: vendor patch unavailable, change freeze during critical business events, or dependency conflicts with validated compensating controls. But paused states need expiry dates, approvers, and periodic review. “Paused until further notice” is not governance; it is drift with a badge.
Evidence rules: what “fixed” means in audits and in reality
Define closure standards in plain language. Acceptable closure usually means one of these: patch applied and validated by rescan; configuration change verified; vulnerable service removed; compensating control documented and approved for bounded time. “Ticket closed” alone should never equal remediation.
Show me the nerdy details
Track three timestamps separately: first seen, ticket created, and verified remediated. This helps distinguish sensor latency from operational delay. It also protects teams from blame when scanner cadence lags but patching happened on time. If your team still mixes manual and scanner-only validation, align your evidence standards with a repeatable pentest report template so closure proof stays auditable.
Priority Overrides That Beat CVSS Every Time
Active exploitation in the wild: override to emergency window
When active exploitation appears, normal queues are too slow. Move directly to emergency change processes. This is where organizations with mature runbooks gain real advantage. You are not abandoning policy—you are executing policy as designed.
Crown-jewel assets and regulated systems: tighter SLA bands
Systems tied to authentication, identity stores, payment workflows, healthcare records, or contractual uptime obligations deserve stricter windows. If your policy treats a demo wiki and production identity provider the same, your SLA is pretending to be fair while being strategically blind.
Compensating controls: when delay is acceptable—and when it isn’t
Compensating controls can buy time, not amnesty. Network segmentation, WAF rules, feature disablement, and monitoring uplift can reduce exploitability while engineering resolves root cause. But controls must be specific, tested, and time-bounded. “WAF enabled” without rule evidence is decorative confidence. Teams running external testing cycles should also align exception language with a clear limitation-of-liability clause and a scoped pen test SOW template so emergency decisions are contract-safe.
Coverage Tier Map: How SLA tightens by exposure
| Tier | Asset Context | SLA Effect |
|---|---|---|
| Tier 1 | Internet-facing + crown jewel | Emergency window |
| Tier 2 | Internet-facing standard services | One band tighter |
| Tier 3 | Internal production | Baseline window |
| Tier 4 | Internal non-production | Baseline + controlled extension |
| Tier 5 | Isolated/decommission path | Exception workflow required |
Neutral next step: Assign every asset one tier before your next monthly SLA review.
Common Mistakes That Quietly Break Your SLA
Treating all “Critical” findings as equal risk
Not all Criticals are born equal. One may require local authenticated access on a segmented host; another is trivially remote on a public endpoint. If your team spends equal effort on both, you’re losing time where it matters most. Prioritization is not favoritism; it is survival math.
Confusing false positives with unverifiable risk acceptance
False positive workflow should include technical proof and reviewer sign-off. Risk acceptance should include business owner approval, expiry date, and compensating control evidence. Blurring these two paths is how overdue tickets disappear into polite ambiguity.
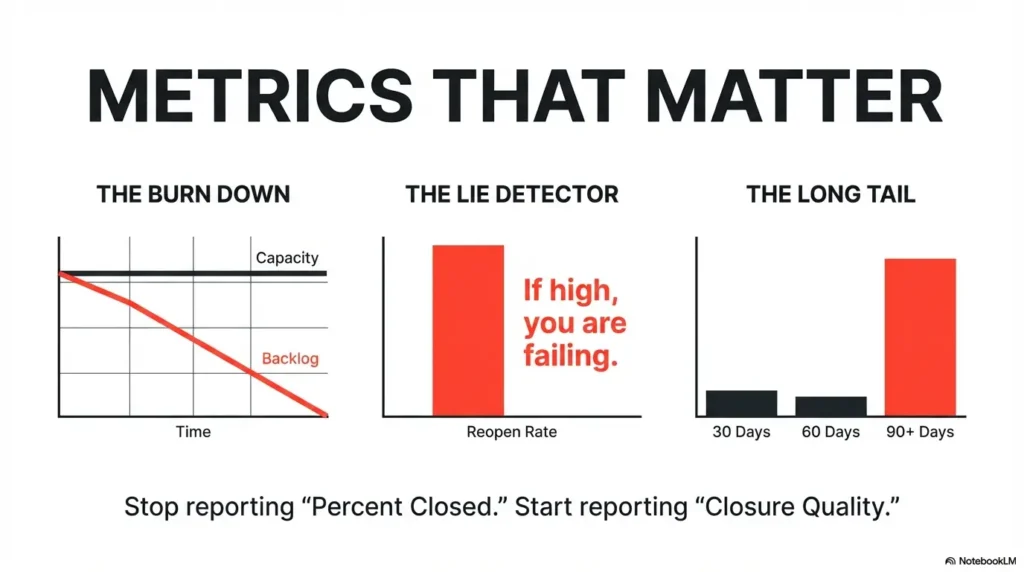
Here’s what no one tells you… reopen rates can erase “good” SLA metrics
If reopened tickets rise, your closure quality is weak. I have seen teams hit 92% SLA compliance while reopen rates climbed past 18%. On paper: success. In reality: recurring exposure and operational churn. Reopen rate is the lie detector for closure discipline.
- Separate false positives from risk acceptances.
- Track reopen rate by team and vulnerability class.
- Require retest evidence for high-impact findings.
Apply in 60 seconds: Add “Reopen reason” as a mandatory field in your ticket workflow.
Don’t Do This: Deadline Theater and Metric Gaming
Closing tickets without retest evidence
“Patched in change ticket XYZ” is useful, but not sufficient for high-risk vulnerabilities. Verification matters. A quick rescan, config snapshot, or control test can prevent embarrassing reopens and strengthen audit narratives.
Mass risk acceptances right before audit windows
This is the classic move everyone recognizes and no one loves. Auditors notice sudden risk-acceptance spikes. So do customer security questionnaires when they ask for exception governance. If your exception curve looks like a ski jump every quarter, your process is signaling distress.
Chasing SLA % while attacker paths stay open
A single open credential theft path can outweigh dozens of timely low-impact fixes. Good programs preserve a dual view: SLA compliance and attack-path reduction. You need both to claim progress with a straight face. If you’re budgeting the work, pair this with a SOC 2 budget calculator so remediation promises map to actual engineering capacity.
Mini Calculator: Can your team hit the target?
Inputs (3): Open critical/high backlog, weekly closure capacity, target weeks.
Formula: Required weekly closures = backlog ÷ target weeks.
If required closures exceed capacity by more than 20%, adjust SLA scope, staffing, or escalation path.
Neutral next step: Run this once per month before leadership reporting.
Who This Is For / Not For
For: SOC managers, vulnerability teams, GRC, IT ops leaders
This model fits teams that juggle scanner noise, patch constraints, customer assurance, and incident pressure. If you own queue health and have to explain outcomes across technical and non-technical stakeholders, this is for you.
Not for: one-off pentest-only programs with no continuous scanning
If your organization only runs annual testing and has no recurring detection pipeline, start smaller. Establish inventory coverage and recurring scans first. An SLA without steady inputs is a compliance costume.
If you have no asset inventory, fix that first (or SLA math fails)
Inventory is the denominator for everything: exposure classification, ownership routing, and metrics confidence. Without reliable ownership and criticality tags, deadlines become guesses with better formatting.
Short Story: The 11:47 p.m. Dashboard Call
A few years ago, I joined a late-night call where everyone celebrated a “green” vulnerability dashboard. Then someone asked one annoying question: “Are these the internet-facing systems?” Silence. We had closed hundreds of medium tickets but left a smaller set of high-risk edge services untouched because ownership metadata was stale.
The ops lead sighed, said he had escalated this twice, and we all did that awkward laugh people do when they realize a chart has been flattering the wrong work. We paused the victory email, rebuilt asset tags over two weeks, and re-ranked the backlog by exposure. Our headline SLA number dipped for one month, which felt painful politically, but incident risk went down in ways that mattered. That was the week I stopped calling dashboards “truth.” They’re maps. Useful maps, yes—but only if the legend is honest.
SLA Policy Design: The Minimum Fields You Need
Severity bands, due dates, and ownership (single throat to choke)
Every ticket should have one accountable owner, not a committee cloud. Shared accountability is lovely in values statements and terrible in incident response. Include required fields: severity, exploitability class, exposure class, due date, owner, and verification method.
Exception workflow, approvals, and expiration dates
Define exception types (technical impossibility, vendor dependency, business freeze, compensating control), required approvers, max duration, and mandatory review cadence. A bounded exception is governance. An unbounded exception is policy debt.
Reporting cadence: weekly ops view, monthly executive view
Weekly reports should focus on queue health and blockers. Monthly reports should focus on risk trend and decision points. Keep both views short, comparable, and brutally consistent.
Quote-Prep List: Gather before SLA rollout
- Top 20 business-critical assets and owners
- Current backlog by severity, exposure, and age
- Patch/change window constraints by platform
- Exception volume from last 2 quarters
- Verification evidence samples (good and bad)
Neutral next step: Use this packet in your first cross-functional SLA workshop.
Show me the nerdy details
Map policy fields directly to system fields in your ticketing platform to avoid manual reconciliation. If your GRC report relies on spreadsheet joins from three tools, your monthly numbers will drift and trust will erode. Teams maturing from ad-hoc testing often transition faster with a standard pentesting tools stack and consistent evidence capture patterns.
Metrics That Actually Prove Risk Reduction
SLA compliance by severity and asset criticality
Start with compliance, but segment it by asset criticality and exposure. A single blended percentage hides too much. Leadership needs to see where late fixes are concentrated.
Mean time to remediate (MTTR) vs age-of-open-vuln distribution
MTTR is useful but can be skewed by quick wins. Age distribution exposes persistent risk pockets: how many findings are older than 30, 60, 90, 120 days? Age bins tell the story MTTR sometimes politely avoids.
Backlog burn-down and reopen rate as integrity checks
If backlog burn-down improves while reopen rate spikes, investigate closure quality. If both improve and exception growth is stable, you are likely reducing real risk. Pair these with trend notes and root-cause actions, not just numbers.
Infographic: Defensible Vulnerability SLA Flow
Exception lane: Approved pause with expiry date, compensating control proof, and review cadence.
- Segment compliance by exposure and criticality.
- Pair MTTR with age bins to expose long-tail risk.
- Track reopen rate as closure quality control.
Apply in 60 seconds: Add one chart: “Open vulnerabilities older than 90 days by asset tier.”
FAQ
Is 30/60/90 still acceptable in 2026?
It can be a workable baseline, but not a complete policy. Most mature programs now apply override logic for active exploitation, internet exposure, and crown-jewel assets. Baseline windows are starting points, not one-size-fits-all answers.
Should KEV-listed vulnerabilities bypass normal SLA?
In most environments, yes. KEV status is a strong indicator for emergency prioritization. If you do not bypass normal windows, document why and prove compensating controls are materially reducing exploitability.
Do we use CVSS base score or environmental score for due dates?
Use both inputs with context. Base score supports consistency; environmental factors and business impact improve precision. The best due-date models incorporate exposure and asset criticality alongside CVSS.
Calendar days or business days for contractual SLAs?
For customer-facing commitments, calendar days are usually cleaner and easier to audit. Internally, some teams track business days operationally while reporting calendar days externally. If you do both, define conversion rules explicitly.
Can compensating controls “stop the clock”?
They can pause or extend within defined bounds, but should not create indefinite deferrals. Require control evidence, approval, and expiration with review dates.
How should cloud misconfigurations fit into vuln SLAs?
Treat high-impact misconfigurations as vulnerability-class findings with the same clock discipline. Identity exposure, public storage, and permissive security groups often warrant aggressive windows because exploit paths are short.
What’s a defensible exception duration?
Use short, renewable windows tied to documented blockers and compensating controls. Fixed limits (for example, 30–90 days depending on severity) with re-approval are generally easier to defend than open-ended exceptions.
How do we handle third-party/vendor-owned vulnerabilities?
Track them under a vendor-risk lane with contractual escalation milestones. Your policy should still define internal actions: containment, monitoring uplift, temporary controls, and customer communication thresholds.
Is patching the only valid remediation?
No. Secure reconfiguration, feature disablement, service decommissioning, or robust compensating controls may be valid. The key is measurable risk reduction and verification evidence.
What evidence is needed to prove closure to auditors?
Typically: change record, technical proof of remediation, and independent verification (rescan or equivalent). Keep evidence linked to ticket IDs and timestamps for traceability. If you audit evidence quality quarterly, a lightweight screenshot naming pattern can dramatically reduce review friction.
When to Seek Help (Legal/Compliance/Incident Context)
If SLA terms are customer-contractual or tied to penalties
Bring legal and compliance in early. Contract language can transform operational targets into financial liabilities. Small wording choices around “discovery,” “notification,” and “cure period” can materially change exposure.
If regulated data is exposed (health, finance, public sector)
Sector obligations can impose timelines and controls outside your standard policy. Coordinate incident response, legal review, and customer communications together. Parallel tracks beat serial handoffs every time.
If exploited vulnerabilities persist past your own Critical window
Treat this as an executive risk event, not a queue management issue. Trigger escalation, document business decisions, and define immediate containment actions. Waiting for the next weekly meeting is how technical debt becomes incident history.
Next Step: One Concrete Action
Build a one-page SLA charter today: severity matrix + clock rules + exception form, then pilot it on one business unit for 30 days before company-wide rollout
Here’s the fast path that actually works in busy environments: keep version 1 short. One page. No novel-length policy. Include four things only: matrix, clock definition, override triggers, exception template. Pilot it with one business unit for 30 days. Measure three outcomes: overdue critical/high count, reopen rate, and exception aging. If those move in the right direction, expand.
This closes the loop from our opening tension: “Which fire first?” You’ll have an answer your engineers can execute, your auditors can verify, and your leadership can defend. In 15 minutes, you can draft the first version and schedule the pilot kickoff. Imperfect and implemented beats perfect and postponed—every single quarter. For teams building broader capability, this often pairs well with a practical penetration testing vs vulnerability scanning framework and a scoped roadmap for post-OSCP security skill growth.
- Start with one-page clarity.
- Pilot for 30 days before broad rollout.
- Judge success by risk trend, not vanity metrics.
Apply in 60 seconds: Book a 45-minute workshop with security, IT ops, and GRC to finalize your v1 charter.
Safety / Disclaimer: This content supports security program design and operational planning, not legal advice. Contractual penalties, sector regulations, and incident circumstances can change acceptable terms. Validate external commitments with your legal/compliance stakeholders.
Last reviewed: 2026-02.