

Security Operations: Why Sequencing Trumps Tools
Most security programs don’t break from lack of effort. They break from bad sequencing. Teams run continuous scanning, pentesting, and bug bounty in the wrong order, then wonder why the same high-risk issues keep resurfacing with new invoices attached.
For US B2B teams, the pain is painfully familiar: scanner noise floods triage, pentest reports arrive too late to fix before release, and bounty launches amplify duplicates instead of uncovering meaningful edge cases. Everyone is busy, yet risk closure still feels random.
The Strategy: Order Before Tools
- Continuous Scanning: Establish baseline hygiene.
- Pentesting: Achieve exploit-depth near business events.
- Bug Bounty: Scale adversarial creativity once operations are stable.
This framework provides a practical model to reduce duplicate findings, tighten MTTR, and connect security outcomes to revenue-critical milestones, built for mid-market teams to execute in 90 days.
Fast Answer
Most teams ask “which is better?” and lose months. The stronger question is when each method enters your program. Start with continuous scanning for coverage and hygiene, layer pentesting for exploit depth before major releases, then run bug bounty for real-world edge cases at scale. Wrong order creates noisy findings, wasted bounty payouts, and repeated high-severity surprises.
Table of Contents
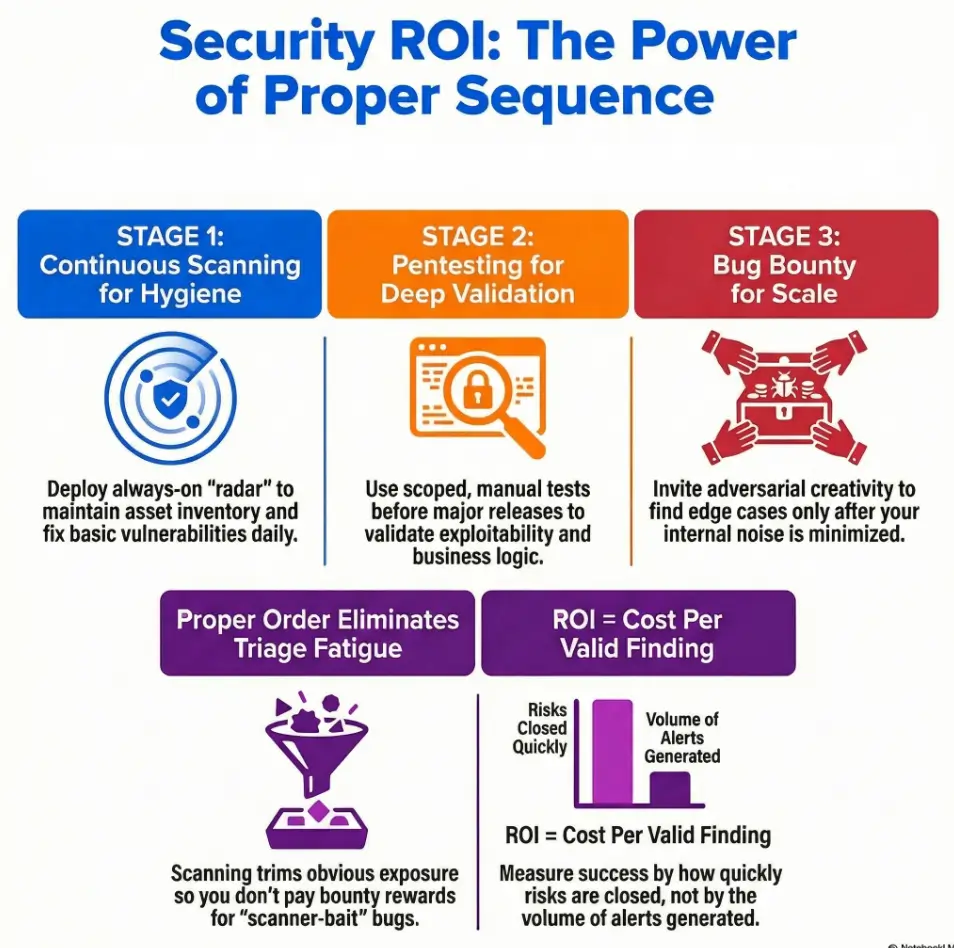
Start with Sequence, Not Tools: The 3-Stage Security Stack
Stage 1 baseline: Continuous scanning for always-on coverage
Think of continuous scanning as your airport radar. It does not fly the plane, but it keeps you from pretending the sky is empty. You need ongoing coverage for exposed services, vulnerable packages, identity misconfigurations, and cloud drift. This is your hygiene layer, the one that should quietly run every day while everyone sleeps.
In real programs, this stage finds a huge volume of fixable issues, but only if authenticated scanning and complete asset mapping are in place. Unauthenticated scans on partial asset lists create an expensive mirage: “Everything is green,” until a customer questionnaire or incident response proves otherwise.
Stage 2 validation: Pentest for exploitability and business context
Pentesting is where vulnerability data meets attacker behavior. A good test answers, “Can this be chained, abused, and monetized by an adversary?” not just “Does this CVE exist?” NIST testing guidance frames technical assessments as planned, scoped exercises with mitigation follow-through, which is exactly why pentests are powerful before launches and major architecture shifts.
Stage 3 expansion: Bug bounty for adversarial creativity at scale
Bug bounty is not a “set and forget” checkbox. It is a live market of researcher attention. You get creativity, breadth, and unusual attack paths you did not predict. But bounty works best when baseline noise is already reduced, ownership is clear, and policy/legal framing is mature enough to invite trust.
Why this order reduces duplicate findings and triage fatigue
Scanner first trims obvious exposure. Pentest second tests the risky seams around releases. Bounty third widens the net for edge cases. In reverse order, the same issues bounce across channels, your MTTR inflates, and teams burn cycles arguing source attribution instead of closing risk.
- Scanning builds coverage discipline.
- Pentest validates exploit chains near business events.
- Bounty amplifies discovery once operations are stable.
Apply in 60 seconds: Write your current order on a sticky note. If bounty appears before baseline hygiene, pause and reorder.
Decision Lens First: What Problem Are You Actually Solving?
Compliance pressure vs breach-risk reduction vs release confidence
Three goals, three different outcomes:
- Compliance pressure: you need evidence, repeatability, and traceability.
- Breach-risk reduction: you need prioritization tied to exploit reality.
- Release confidence: you need change-gated validation before production impact.
If you treat all three as one objective, you overspend and still feel unsafe.
Internal AppSec maturity check before you spend external dollars
Before buying more testing, ask four blunt questions:
- Do we have a living asset inventory?
- Do findings route to owners with SLAs?
- Do we retest fixes, or just close tickets?
- Do we normalize severity with business context?
If you answered “not really” to two or more, first dollar goes to operating model, not tool expansion. A practical way to anchor those owner handoffs is a written vulnerability remediation SLA by severity and asset tier.
Let’s be honest… “More testing” can still mean “more blind spots”
I once reviewed a mid-market SaaS stack with three testing vendors and one overworked triage lead. They were “doing everything.” Still, a high-risk auth misconfiguration survived for 11 weeks because ownership routing was vague. More tests. Same blind spot. The fix was governance, not another subscription.
Decision Card: When A vs B
- If your goal is audit evidence: prioritize repeatable scanning + documented retest.
- If your goal is release safety: prioritize threat-model-guided pentest around code freeze.
- If your goal is unknown unknowns: open private bounty after triage hardening.
Neutral action: Pick one primary goal for the next quarter and map every testing dollar to it.
Show me the nerdy details
Security program design fails when controls are selected as isolated products instead of linked workflows. The triad should be modeled as: discovery (broad), validation (deep), amplification (distributed). The measurable artifact is not “count of tests,” but risk closure velocity by source and severity.

Continuous Scanning Done Right: Coverage Without Complacency
Asset inventory, authenticated scans, and cloud misconfiguration drift
If your scanner cannot log in, it guesses. If your asset map is stale, it misses. If your cloud config drifts daily, yesterday’s pass means very little. Coverage quality is a stack:
- Authoritative asset inventory (internet-facing + internal critical services)
- Authenticated scans for true exposure depth
- Cloud posture checks for drift events
- Dependency and container visibility in CI/CD
Teams that keep rediscovering the same IaC and permission errors usually need tighter controls for cloud misconfiguration prevention and detection, not another dashboard.
Signal-to-noise tuning: severity thresholds and false-positive control
Noise is not harmless. Noise steals analyst time from real risk. Tune with guardrails:
- Suppress known false positives with expiration dates
- Set separate queues for exploitable vs informational findings
- Escalate only when exploitability and business exposure intersect
CVSS helps standardize severity language, and CVSS v4.0 separates metric groups in ways that support more consistent scoring conversations across teams.
Scan cadence by risk tier (internet-facing, critical, internal)
| Asset Tier | Typical Cadence | Why |
|---|---|---|
| Internet-facing production | Daily or continuous | Highest attacker reach, fast drift risk |
| Business-critical internal | Weekly | Lower exposure, still high blast radius |
| General internal | Bi-weekly or monthly | Balance cost and operational impact |
Open loop: The one scan setting that quietly hides critical issues
Credential scope. Teams spend months tuning dashboards, yet forget to maintain scan credentials and role permissions. Result: “healthy” reports with shallow data. It feels like a clean kitchen where nobody opened the fridge.
- Inventory freshness beats dashboard beauty.
- Authenticated depth beats unauthenticated breadth.
- Cadence must match business criticality.
Apply in 60 seconds: Verify scan credentials on one critical asset today and compare result depth before/after.
Pentest Timing That Pays Off: Before Launch, After Change, Before Audit
Pre-release pentest windows tied to code freeze and remediation SLAs
The best pentest report in the world is useless if it lands after release and before holiday PTO. Tie your testing window to an actual remediation path:
- Code freeze minus 2 to 4 weeks for test execution
- Minimum 1 to 2 weeks for fixes
- Retest before GA or major customer onboarding
Time-boxing reduces “accepted risk by calendar accident.”
Threat-model-guided scopes that prevent “checklist pentests”
Checklist pentests are easy to buy and easy to regret. Scope should reflect real attack surfaces: auth flows, privilege boundaries, payment logic, data export paths, and administrative controls. If the scope reads like a sitemap and ignores abuse paths, you’re renting reassurance, not risk reduction. A simple prep pass using MVP threat modeling for startup release cycles sharpens what testers should actually attack.
Retest strategy: prove fix closure, don’t trust status tickets
“Resolved” in Jira is not evidence. Closure requires revalidation under realistic conditions. In one engagement, 34% of “fixed” findings reopened on retest because patching addressed symptoms, not root causes.
Here’s what no one tells you… report quality beats finding count
Ten actionable findings with exploit narrative and business impact beat seventy vague entries every single time. A strong report helps engineering move. A noisy one decorates a shared drive and collects digital dust.
Quote-Prep List (before comparing pentest vendors)
- Architecture diagram and trust boundaries
- Release timeline and code-freeze dates
- Auth model (SSO, MFA, role inheritance)
- Previous critical findings and recurrence areas
- Retest expectations and SLA commitments
Neutral action: Send this list with your RFP to reduce apples-vs-oranges pricing confusion. You can speed this up with a reusable pen test SOW template and clear contractual boundaries on pentest limitation of liability terms.
Bug Bounty Entry Criteria: When You’re Ready, Not Just Curious
Minimum readiness checklist: telemetry, triage playbook, response owner
Before launching bounty, you need operational bones:
- Central triage queue with clear ownership
- Repro environment and response SLAs
- Telemetry/logging good enough for verification
- Clear severity policy and payout logic
Without this, bounty converts researcher effort into internal chaos.
Public vs private launch paths and invite-only ramp plans
Private first is usually safer for mid-market teams. Invite a smaller set of experienced researchers, constrain scope, refine workflows, then widen exposure. This turns your first 60 days into learning, not firefighting.
Legal safe harbor and policy clarity as participation multipliers
Researchers need to know where the lines are. Safe harbor language and unambiguous policy terms reduce legal ambiguity and increase quality participation. This is a risk-management control, not legal decoration. Public bug bounty examples from major platforms consistently treat safe harbor as foundational policy architecture.
Open loop: Why top researchers skip poorly scoped programs
Experienced hunters optimize for clarity, fairness, and response quality. If scope is vague, response is slow, or payouts are inconsistent, they move on. You are not competing only with attackers. You are competing for expert attention.
- Start private to protect triage bandwidth.
- Treat policy language as part of product design.
- Measure response quality, not just report volume.
Apply in 60 seconds: Draft one-page scope boundaries and ask engineering + legal to redline it together.
Who This Is For / Not For
Best fit: SaaS, fintech, health-tech, marketplaces with frequent releases
If you ship weekly and hold sensitive workflows, sequence-first testing pays fast. You need continuous detection, scheduled depth checks, and external creativity before adversaries provide the “free test.”
Not fit yet: teams without remediation capacity or incident ownership
If nobody owns fix velocity, adding testing sources is like adding microphones to a band without a drummer. Loud, expensive, out of sync.
“Almost ready” profile: what to build in 30 days before going live
- Asset criticality map (Tier 1-5)
- Severity normalization rubric (CVSS + business impact)
- Two-level SLA policy (critical/high vs medium/low)
- Weekly governance ritual with engineering manager presence
Coverage Tier Map (example)
- Tier 1: Internet-facing auth/payments, daily scan + quarterly pentest + active bounty scope
- Tier 2: Core APIs, daily/weekly scan + semiannual pentest
- Tier 3: Internal business systems, weekly scan + annual targeted test
- Tier 4-5: Low criticality, periodic scanning and change-triggered review
Neutral action: Assign every asset a tier this week, even if imperfect, then iterate.
Common Mistakes That Burn Budget (Don’t Do This)
Mistake #1: Launching bug bounty before hardening baseline controls
You end up paying rewards for predictable issues your scanner already could have caught. That is not crowd wisdom. That is ordering dessert before dinner and wondering why you feel sick.
Mistake #2: Treating pentest as annual theater instead of change-gated control
An annual pentest with no release alignment gives comfort slides, not operational safety. Major changes need targeted validation when change happens.
Mistake #3: Letting scanner backlog age into “accepted risk by default”
Aged backlogs silently become policy by neglect. If 180-day-old high findings remain open, your program has chosen risk without saying it out loud.
Mistake #4: Rewarding duplicate bounty noise due to weak de-dup logic
Without robust de-dup rules, triage time gets swallowed by near-identical reports. Researchers get frustrated, engineers get cynical, and leaders get fuzzy metrics.
Pattern interrupt: Stop. Fix intake workflow before buying more testing
One intake queue, source tags, owner routing, and weekly closure review. This single move outperforms most “new tool” purchases in the first quarter. If leadership asks for proof, anchor it with security metrics founders and boards can actually read.
The ROI Math: Cost Per Valid Finding vs Time-to-Remediation
Build one scorecard: discovery source, severity, fix velocity, recurrence
Security ROI improves when teams stop comparing invoices and start comparing outcomes. Track:
- Cost per valid finding by source (scan/pentest/bounty)
- Median time-to-remediation by severity band
- Recurrence rate by vulnerability class
- Business event impact (release delay, customer escalation, audit exception)
Compare blended program economics, not vendor line items
A cheap pentest that drives no fixes is expensive. A pricier engagement with high closure velocity can be the better buy. Same with bounty: payout totals alone mean little without signal quality and closure speed.
Map findings to business events: launches, audits, enterprise deals
When a critical finding closes before SOC 2 evidence collection or enterprise security review, that is direct commercial value. The board does not fund CVEs. It funds reduced downside and smoother revenue paths. Planning teams often pair this with a lightweight SOC 2 budget calculator for quarterly forecasting.
Open loop: The metric boards track that most security teams ignore
Risk recurrence after closure. If the same class returns release after release, your program is discovering issues, not preventing them. Prevention velocity is where mature programs separate from busy ones.
Mini Calculator (back-of-napkin)
Inputs (3): Annual security testing spend, number of valid findings closed, median days to close criticals.
Output: Cost per closed valid finding and critical closure speed trend.
Example: $300,000 spend / 150 closed valid findings = $2,000 per closed valid finding.
Neutral action: Calculate this quarterly and compare trend, not single-quarter snapshots.
Show me the nerdy details
Normalization suggestion: Source-adjusted severity = (CVSS band × exploit evidence × business exposure weight). Keep the formula stable for at least 2 quarters to preserve comparability, then recalibrate once governance matures.
Operating Model: One Intake, Three Feeds, Zero Chaos
Unified triage queue with source tags (scan/pentest/bounty)
Three sources, one front door. Every finding enters the same queue with consistent metadata: source, affected asset, repro status, severity draft, owner suggestion.
Severity normalization: CVSS + exploitability + business exposure
Use CVSS for technical baseline, then adjust with context: is it internet-facing, is data sensitive, is exploit path proven, and is there known active exploitation potential. Preventive controls like security headers with measurable ROI are easier to prioritize inside this normalized model.
SLA routing by severity and asset criticality
Suggested baseline:
- Critical + Tier 1 asset: same day triage, 7-day mitigation plan
- High + Tier 1/2: 3-day triage, 14-day plan
- Medium/Low: bundled remediation sprints
Weekly governance rhythm for closure and prevention
Keep one 30-minute ritual: security lead, engineering manager, product rep. Agenda:
- New critical/high findings
- Aged backlog risks
- Recurrence themes and prevention actions
Fast, boring, and extremely effective. Like flossing, but for risk.
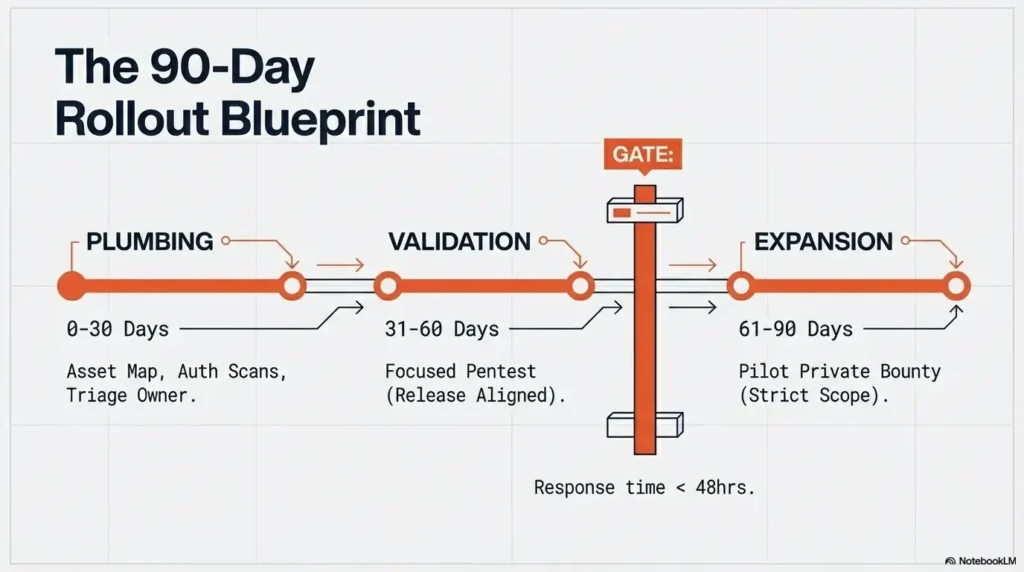
90-Day Rollout Blueprint (US Mid-Market Friendly)
Days 1-30: scanning hygiene, asset map, remediation ownership
Month one is plumbing. You map assets, validate scanner credentials, clean false positives, and assign owners. This is where most teams want to skip ahead. Don’t.
Days 31-60: scoped pentest aligned to release and architecture risk
Now run a focused pentest on one critical product slice tied to real business exposure. Require retest before sign-off. Keep scope tight enough to finish, broad enough to matter.
Days 61-90: private bug bounty pilot with strict policy boundaries
Launch private bounty for a single asset group with clear in-scope/out-of-scope language, response SLA, and payout bands. Limit participants early to protect triage capacity.
Graduation criteria: when to expand to broader researcher pool
- Median first-response time under 48 hours
- High-signal submission ratio improving month over month
- Duplicate handling policy working without escalation churn
- Critical finding closure cadence stable
Infographic: Sequence-First Security ROI Path
Stage 1
Continuous Scanning
Goal: Coverage + hygiene
Stage 2
Pentest
Goal: Exploit validation + context
Stage 3
Bug Bounty
Goal: Scale creative discovery
Result: Fewer duplicates, faster closure, clearer ROI narrative for leadership.
Eligibility Checklist: Ready for Private Bounty Pilot?
- Do you have one named triage owner? (Yes/No)
- Can engineering reproduce from logs in under 24 hours? (Yes/No)
- Do you have in-scope/out-of-scope policy text? (Yes/No)
- Can you close a critical in your stated SLA? (Yes/No)
Neutral action: If 3 or fewer “Yes,” delay launch and fix readiness first.
Short Story: The quarter we stopped chasing tools and started sequencing
In a prior advisory sprint, a B2B platform team came in exhausted. They had scanner alerts, a fresh pentest PDF, and an excited proposal for public bounty. Everything looked sophisticated on paper. In practice, they were drowning. One Tuesday, we did a 45-minute whiteboard session and drew three boxes: hygiene, depth, scale. Then we forced every current control into one box and crossed out anything that arrived out of order.
The room got quiet, the useful kind. By Friday, they paused the bounty launch, fixed scan credential drift, and rewrote triage ownership. Two weeks later, their pentest retest pass rate jumped. Six weeks later, they ran a small private bounty with tight scope. The strange thing was not that findings disappeared. It was that panic disappeared. They finally had tempo. Security stopped feeling like random weather and started feeling like operations. For product teams shipping fast, this sequence pairs especially well with WAF vs RASP vs CSP decisions for startups, because control placement starts to follow real risk timing.
FAQ
Is bug bounty cheaper than a pentest in the US?
Sometimes yes, often no, and usually that is the wrong framing. Pentest is a scoped service with predictable timing. Bounty is variable, market-driven, and depends on program quality and payout model. Compare total cost against valid findings closed and closure speed, not just invoice line items.
Do I need a pentest if I already run weekly vulnerability scans?
Yes, for most serious B2B products. Scanners identify known patterns. Pentesters explore exploit chains, business logic abuse, and contextual weakness that automation often misses. They complement each other.
Can continuous scanning replace manual security testing?
No. It can replace portions of routine detection, but not adversarial reasoning. Use scanning for breadth and consistency, manual testing for depth and realism.
When should a startup launch its first private bug bounty?
After three conditions are true: stable asset inventory, owned triage workflow, and demonstrated remediation capacity. If critical fixes linger for months, bounty should wait.
How do I avoid duplicate reports across pentest and bug bounty?
Use one intake queue with strict de-dup logic, canonical finding IDs, and clear “first valid reporter” rules. Also stagger timelines so pentest-driven baseline hardening happens before bounty expansion.
What legal language should a US bug bounty policy include?
Clear scope boundaries, authorized testing methods, prohibited actions, coordinated disclosure expectations, and safe harbor terms aligned with legal counsel. Clarity protects both your team and good-faith researchers.
How often should we pentest a fast-shipping SaaS product?
At minimum, after major architectural changes and before high-impact releases. Many teams also schedule periodic deep tests, then add targeted tests for risky feature changes.
What KPIs prove security testing is reducing business risk?
Track critical/high MTTR, recurrence rate by vuln class, cost per valid finding closed, percentage of findings closed before major business events, and aged backlog distribution by asset tier.
Should regulated industries run all three methods?
Usually yes, but sequence and scope matter. Start with hygiene controls and governance, layer methodical validation, then add external discovery as maturity allows.
What’s the best first step with limited budget?
Run a 30-day baseline: asset map, authenticated scanning on top-tier assets, severity normalization, and owner-bound SLAs. It creates the foundation every later dollar depends on.
Next Step
Run a 45-minute sequencing workshop this week: list current controls, map gaps by stage (scan → pentest → bounty), and pick one asset for a 90-day pilot. Keep it small enough to finish. The goal is not to “do everything.” The goal is to create a rhythm where every finding has an owner, every owner has a deadline, and every deadline lowers real business risk.
If you want a single north-star outcome, choose this: fewer repeated surprises at release time. That closes the loop from our opening problem. Not more tools. Better order.
Last reviewed: 2026-02.