


From .env Hell to Controlled Operations: A Pragmatic Secrets Management Guide
Most startups don’t get burned by sophisticated attacks first—they get burned by convenience. A production token copied into chat, a screenshot with one unblurred corner, or a “temporary” .env file that quietly becomes permanent. That’s how secrets management turns from a developer shortcut into an operational liability.
The pain isn’t theoretical: secrets sprawl across repos, CI variables, local machines, and third-party tools faster than teams can track ownership. When something breaks, nobody can answer the two questions that matter most: Who can revoke access, and how fast?
Keep delaying, and the cost shows up where it hurts most: avoidable outages, stalled enterprise deals, and trust gaps during security reviews.
This guide provides the minimum setup for 5–50 person teams shipping weekly to end secret sprawl without an enterprise platform team:
- One Source of Truth: Centralized management for all environments.
- Identity-Based Access: Secure permissions tied to the individual.
- Rotation & Revocation: A model your team can actually run under pressure.
- Audit-Ready Evidence: Real security without the “process theater.”
No jargon marathon. No compliance cosplay. Just the fastest path to security.
Table of Contents
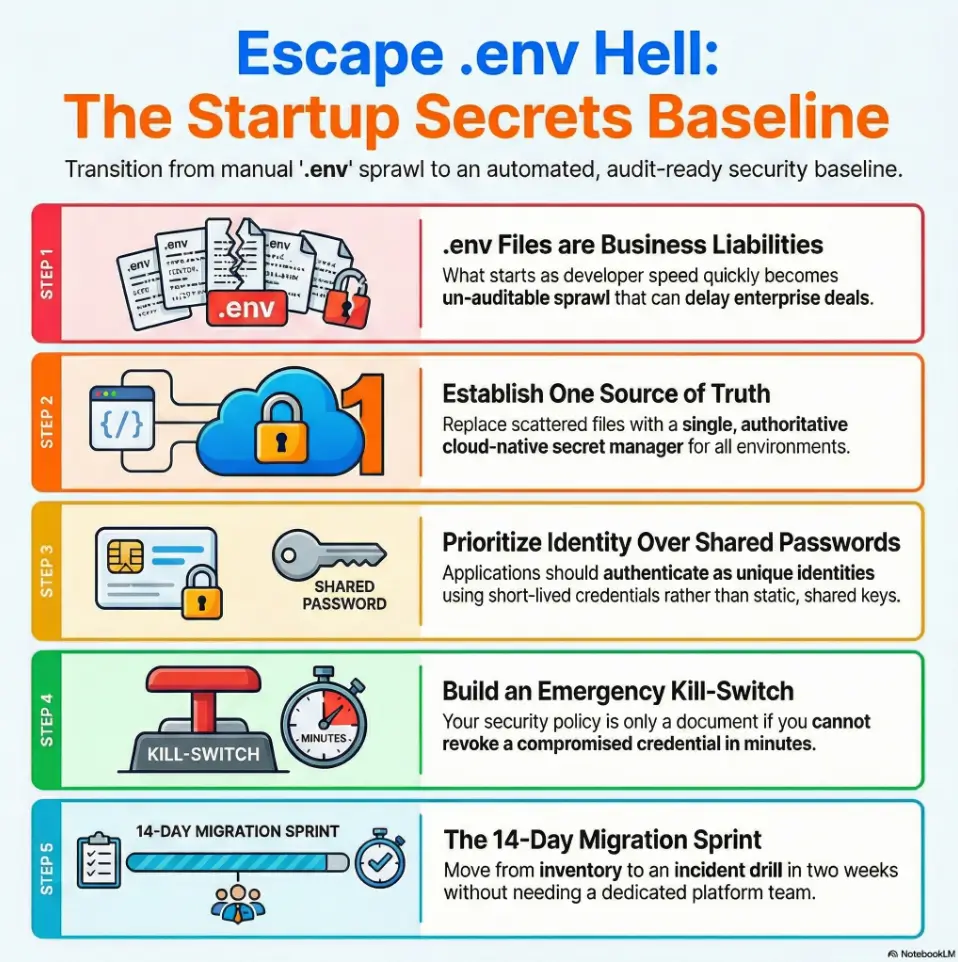
Why .env Breaks at Scale Before You Notice
The hidden failure mode: convenience today, breach path tomorrow
.env files are not evil. They are just too easy to misuse. At team size 3, they feel like speed. At team size 25, they become invisible infrastructure with no ownership, no audit trail, and no clean revocation story. That’s the trap: the same thing that made you fast at week 1 makes you brittle by quarter 3.
I once reviewed a startup stack where the same payment API key appeared in eight places: two repos, one CI variable group, a local bootstrap script, one runbook screenshot, and three laptops. No one intended that sprawl. It happened because nobody designed identity boundaries early.
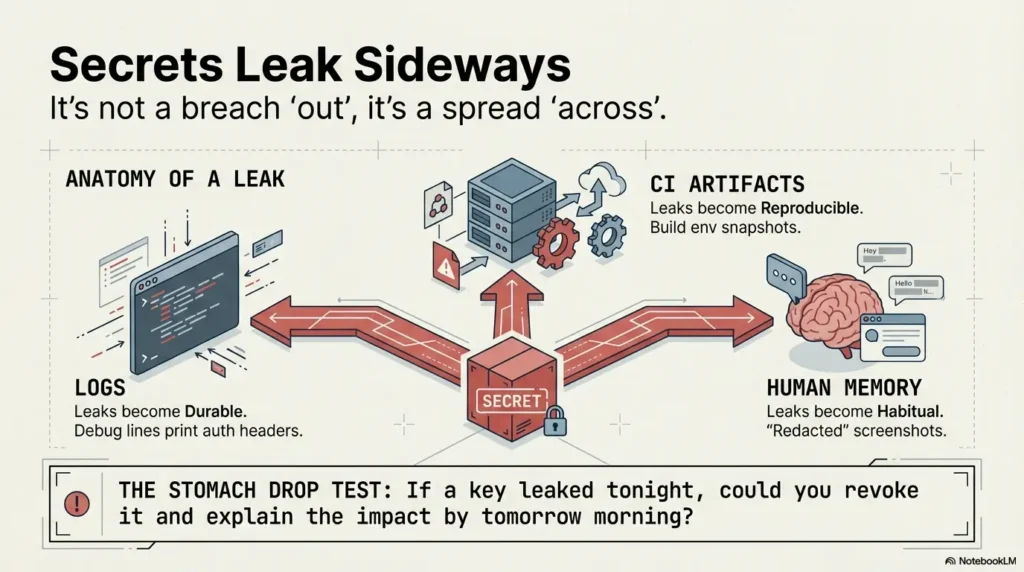
How leaked tokens spread across logs, laptops, and CI artifacts
Secrets leak sideways more often than they leak “out.” A debug line prints auth headers. A build artifact stores environment snapshots. A teammate shares a redacted screenshot that missed one corner pixel. Suddenly your “private” token exists in five systems with different retention rules.
- Logs make leaks durable.
- CI variables make leaks reproducible.
- Human memory makes leaks habitual.
Translation: secret management is less about crypto and more about operational containment.
Let’s be honest… plaintext secrets feel “temporary” until they become permanent
“Temporary” keys often survive 9–18 months. Nobody plans that either. The first customer escalation or security questionnaire exposes the gap: no one can answer who accessed what, when, and why. That’s not just a security risk; it’s a revenue risk.
.env stops being a developer convenience and becomes a business liability earlier than most teams expect.
- Sprawl happens without malicious intent.
- Identity design errors look like secret leaks.
- Audit gaps can delay enterprise deals.
Apply in 60 seconds: Pick one production secret and list every place it lives today.
Minimum Viable Secrets Stack for a 5–50 Person Startup
Layer 1: centralized secret source (single system of record)
Start with one authoritative store. Not two. Not “temporary plus legacy.” One. If engineers can’t answer where the truth lives in three seconds, your architecture is already too loose.
Good first-pass options include cloud-native secret managers or a managed vault setup. Keep naming consistent (service + environment + purpose) and tag ownership from day one.
Layer 2: identity-based access (service identity over shared passwords)
Move from “who knows the key” to “which identity can request a short-lived credential.” Service accounts, workload identities, and scoped IAM policies beat shared static passwords every time.
In plain terms: apps should authenticate as themselves, not as “the team.”
Layer 3: rotation + revocation workflow (because incidents are timing problems)
Rotation matters, but revocation speed matters more. A strong baseline gives you both: scheduled renewal plus emergency kill-switch procedures. If you can’t revoke a compromised credential in minutes, your “policy” is only a document.
What “minimum” means—and what you can defer safely for 6 months
Minimum does not mean weak. It means focused:
- Central store: yes.
- Per-service scoped access: yes.
- Rotation for crown-jewel secrets: yes.
- Complex policy engines and multi-region vault federation: defer if your risk doesn’t require it yet.
Show me the nerdy details
Use envelope encryption patterns where practical, and separate key management boundaries from application ownership boundaries. Keep bootstrap trust roots extremely narrow. If you’re on Kubernetes, evaluate workload identity and external secret sync paths carefully to avoid static token reintroduction.
- One source of truth prevents policy drift.
- Identity-based access reduces lateral spread.
- Rotation + revocation turns panic into procedure.
Apply in 60 seconds: Define your “crown-jewel” top 5 secrets and assign explicit owners.
Who This Is For (and Who Should Skip This for Now)
For: seed to Series B teams shipping weekly with cloud-native workloads
If you deploy often, touch customer data, and have more than one engineer merging to production, you are in scope. Especially if your team uses AWS, GCP, Azure, Kubernetes, GitHub Actions, GitLab CI, or Terraform pipelines.
Not for: solo prototypes with no external users or regulated data
If you’re pre-user, pre-revenue, and still proving problem/solution fit, don’t overbuild. Start with safer local dev patterns and keep secrets out of source control. Graduate to the full baseline the moment real users or third-party data arrive.
Decision checkpoint: are you protecting customer trust or internal convenience?
Here’s the blunt test: if a key leaked tonight, would your team detect it, revoke it, and explain impact by tomorrow morning? If the answer is “probably not,” this migration should jump near the top of your sprint queue.
Eligibility Checklist: Is this sprint worth doing now?
- Yes/No: We have production users.
- Yes/No: At least 2 people can deploy to prod.
- Yes/No: We complete security questionnaires for deals.
- Yes/No: We have no reliable emergency credential revocation drill.
Neutral action: If two or more answers are “Yes,” schedule the 14-day sprint this quarter.
Start Here First: Protect Production Without Slowing Developers
Why production-first hardening gives the best risk reduction per hour
Teams often start in dev because it feels easier. That’s backwards for risk. Production-first cuts real exposure immediately and gives you cleaner migration lessons before touching every laptop workflow.
One team I coached did this in 11 business days: prod API credentials first, staging second, local dev last. Result? Fewer outages than their previous “all-environments-at-once” attempt.
Dev/staging strategy: pragmatic guardrails without ceremony
Keep local development humane. Nobody wins if secret management turns npm run dev into a ritual. Use scoped dev credentials, short TTL where possible, and clear fallback behavior for offline work.
How to phase rollout by blast radius, not by team politics
Sort migrations by damage potential:
- Payment, auth, database admin creds
- Customer-data APIs
- Internal tooling tokens
- Low-impact integrations
When debate starts, blast radius ends it.
Access Model That Actually Works: Human vs Workload Secrets
Humans: SSO, MFA, and scoped read/write boundaries
Human access should flow through identity providers with MFA and least privilege. A developer who debugs staging should not automatically read production payment secrets. Break glass access should be explicit, logged, and time-bound.
Mentioned often in customer reviews: teams that can show this model answer questionnaires faster and with less contradiction.
Workloads: short-lived credentials and runtime injection
Workloads should fetch secrets at runtime via identity, not carry static tokens baked into images or committed files. If your container can run for weeks with the same high-privilege credential, it’s one compromise away from a long bad week.
CI/CD: brokered access instead of long-lived pipeline secrets
CI is where old habits hide. Replace “permanent CI secret variables” with brokered, short-lived credentials issued during job execution. Keep scopes narrow: deploy-only jobs should not gain read access to broad production data stores.
Here’s what no one tells you… most “secret leaks” are identity design leaks
When access boundaries are vague, secrets appear to leak everywhere because everyone can touch everything. Tight identity design reduces leak impact even when leaks still occur.
Decision Card: Static Secret vs Short-Lived Credential
Choose static only for low-impact, non-prod, short-horizon prototypes.
Choose short-lived for production services, CI jobs, and anything customer-facing.
Trade-off: Slight setup complexity now vs dramatically lower incident blast radius later.
Neutral action: Convert one CI pipeline from static token to brokered access this week.
Common Mistakes That Keep Startups in .env Hell
Mistake #1: “One secret for everyone” shared across services
This kills traceability. If four services use one key, you lose forensic clarity during incidents. Use per-service credentials. Yes, it’s more objects to manage. It’s also the difference between a surgical fix and a company-wide outage.
Mistake #2: rotation without dependency mapping (outages by surprise)
Rotation fails when hidden consumers exist. Inventory dependencies before rotating. Otherwise your “security improvement” becomes a pager event at 2:13 a.m.
Mistake #3: storing secrets in build-time artifacts
Never bake secrets into container layers, static bundles, or generated config archives. Build artifacts travel farther and live longer than intended.
Mistake #4: ignoring secret sprawl in third-party tools
Secrets hide in monitoring tools, BI connectors, incident bots, and vendor dashboards. Track external SaaS endpoints in your inventory or your map is fiction.
Mistake #5: treating incident response as an afterthought
Incident response is not a PDF. It’s a rehearsal habit. Teams that practice revocation and rollback recover faster and speak more confidently to customers.
“Security debt grows quietly. Then it shows up all at once—usually during your most important sales cycle.”
Don’t Do This: 7 Anti-Patterns That Create Silent Security Debt
Committing .env to private repos “just for now”
Private is not the same as safe. Repo access expands over time.
Reusing API keys across environments
If staging key misuse can touch production data, you have no real boundary.
Long-lived root credentials in automation
Automation should run on scoped identities. Root tokens in bots are breach multipliers.
“Temporary” Slack/Notion sharing of keys
Searchable chat history is forever-ish. Treat message systems as hostile for secret storage.
Backups that accidentally archive revoked secrets
Revoked does not mean erased. Validate backup retention and restoration pathways.
Rotation schedules with no ownership
A calendar without owners is theater. Assign accountable humans.
No kill-switch plan for compromised credentials
If you cannot answer “who pushes revoke” in 10 seconds, you don’t have a kill switch.
- Chat tools are not vaults.
- Private repos are not secret managers.
- Root credentials should not power routine automation.
Apply in 60 seconds: Ban secret sharing in chat and publish one approved emergency channel today.
The 14-Day Migration Sprint (Without a Platform Team)
Days 1–2: inventory secrets and rank by blast radius
Create a top-20 list: secret name, owner, environment, consumers, TTL, revoke path. If a field is unknown, write “unknown” explicitly. Hidden uncertainty is the real risk indicator.
Days 3–5: stand up centralized store and IAM boundaries
Define naming conventions and scope policies before bulk migration. Use one small service as a pilot to validate retrieval patterns and latency expectations.
Days 6–9: migrate production apps and CI access paths
Move crown-jewel secrets first. Run staged rollout with rollback hooks. Keep a live migration log to prevent repeated mistakes.
Days 10–12: add rotation playbooks + alerting
Implement automatic rotation where feasible. For manual rotation cases, add checklist playbooks and pager triggers tied to failure signals.
Days 13–14: tabletop incident drill and rollback rehearsal
Simulate compromised credential events. Measure time-to-detect, time-to-revoke, and time-to-recover. If revocation takes more than 30 minutes for high-impact secrets, tighten process immediately.
Open loop: what breaks first during migration—and how to preempt it
The first break is usually implicit dependencies: old cron jobs, forgotten scripts, or vendor webhooks. Preempt with dependency discovery and temporary dual-read windows (short and controlled).
Mini Calculator: Secret Rotation Capacity
Inputs:
- High-impact secrets count
- Average minutes to rotate one secret safely
- Available engineer-hours per month
Output:
If total monthly rotation minutes exceeds available capacity, reduce scope or increase automation before committing policy dates.
Neutral action: Estimate this once before announcing rotation SLAs.
Tooling Choices: Managed Service vs Self-Hosted Tradeoffs
Managed approach: speed, reliability, and lower ops overhead
Managed services usually win for early-stage teams on time-to-value. You get operational reliability, better defaults, and less midnight maintenance debt. For most seed-to-Series B teams, this is the pragmatic first move.
Self-hosted approach: control, cost profile, and operational burden
Self-hosted can work if you truly need custom controls and have on-call maturity. But be honest: if you can’t staff reliability for it, “control” is often an illusion.
Cost lens: total cost of secret incidents vs platform spend
Cheaper monthly tooling can become expensive after one leak-related outage, one delayed enterprise deal, or one customer escalation cycle. Model total cost, not sticker price. If you need a practical model, pair this with a SOC 2 budget calculator for early-stage teams and include incident-response labor in the estimate.
Open loop: when your “cheap” option becomes the expensive one
It happens when hidden toil arrives: upgrades, HA fixes, backup tests, policy drift, and incident handling. If your team is already tight, managed often costs less in real life.
| Year Stage | Typical Team Profile | Practical Choice | Notes |
|---|---|---|---|
| 0–1 | Tiny team, fast shipping | Managed secret store | Optimize for speed + fewer ops surprises |
| 1–2 | Growth, first enterprise asks | Managed + stronger IAM boundaries | Focus on evidence and revocation drills |
| 2+ | Dedicated security/platform maturity | Evaluate hybrid or self-hosted | Only if on-call and reliability are funded |
Neutral action: Choose based on staffing reality, not ideology.
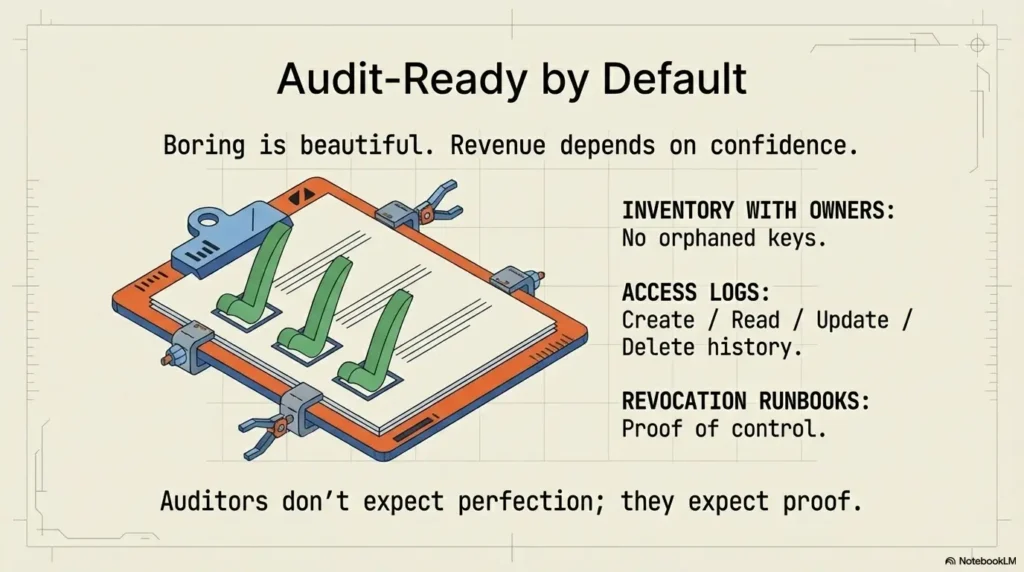
Audit-Ready by Default: Logs, Ownership, and Evidence Trails
Minimum logs to retain for SOC 2 and customer questionnaires
At minimum, record secret create/read/update/delete events, policy changes, authentication source, and failure events. Keep retention aligned with your customer commitments and internal incident timelines.
Auditors and procurement teams don’t expect perfection—they expect consistency and proof. The most common blocker is not controls themselves, but weak evidence packaging during a vendor security questionnaire response cycle.
Ownership matrix: who can create, rotate, revoke, approve
Define four roles clearly: creator, operator, approver, incident commander. One person can hold multiple roles in small teams, but role boundaries must still be explicit and documented.
Evidence automation for security reviews and enterprise deals
Build lightweight exports: access logs, rotation history, IAM policy summaries, and incident drill outcomes. These artifacts turn questionnaire firefighting into repeatable response packets. If you want KPI clarity, track them with a focused set of security metrics that founders can actually review monthly.
Security Questionnaire Quote-Prep List
- Secret inventory with owners
- Rotation policy and last execution dates
- Emergency revocation runbook
- Access log samples
- CI/CD credential flow diagram
Neutral action: Save these five artifacts in one shared “security responses” folder.
Infographic: From .env Chaos to Audit-Ready Baseline
List top-20 secrets, owners, environments, revoke paths.
One source of truth, consistent naming, tagged ownership.
Human SSO/MFA, workload identity, scoped policies.
Scheduled rotation + emergency kill switch drills.
Outcome: fewer leaks, faster incident response, cleaner customer trust signals.
Show me the nerdy details
If you use cloud KMS and a separate secret manager, document boundary responsibilities explicitly. KMS handles key operations; secret managers handle secret lifecycle and access governance. Avoid vague language in policies that blurs those responsibilities.
Next Step: One Concrete Action for Today
Run a 60-minute “secret sprawl” workshop and produce a top-20 credential risk list
Invite one engineer from backend, one from DevOps/SRE (or the nearest equivalent), and one product owner who understands customer impact. In 60 minutes, map the top 20 credentials by blast radius and assign owners.
Assign one owner per high-impact secret with rotation date + revocation runbook
No owner, no reliability. Keep runbooks short: trigger, revoke steps, rollback, validation checks, notification path. Print it if you must. You want muscle memory, not poetry, when something goes wrong.
Short Story: Two winters ago, a startup team called me after an enterprise pilot stalled. Not because of a breach—because of uncertainty. Procurement asked who could revoke production API keys after-hours and how fast. Silence on the call. One engineer finally said, “I think I can, but I’ve never done it live.” That sentence cost them two weeks and a painful trust gap.
We did a one-hour sprawl workshop, assigned owners, tested revocation with a staged key, and documented a 14-minute incident path end-to-end. The buyer didn’t applaud; they simply resumed. That’s the quiet truth about security work: the best outcomes feel boring. Boring is beautiful when revenue depends on confidence. If you need a planning template before this workshop, use an MVP threat modeling framework for startup teams to prioritize what actually matters first.
This guide is educational and operational—not legal, compliance, or incident-response counsel. Adapt controls to your stack, threat model, customer commitments, and contractual requirements. If you suspect compromise, face enterprise escalations, manage regulated exposure, or keep seeing outages tied to rotation/access failures, bring in a qualified security engineer or consultant immediately. For external testing engagements, align expectations early with a penetration test SOW template, define response windows through a vulnerability remediation SLA policy, and clarify legal boundaries with a pentest limitation-of-liability clause guide.
Last reviewed: 2026-02.
FAQ
Do we need secrets management before SOC 2 Type I?
You can technically start SOC 2 readiness without a perfect secrets program, but you’ll move faster and answer evidence requests more cleanly if you already have centralized storage, access controls, and rotation records.
Can we keep .env for local development safely?
Yes, with guardrails: no production secrets in local files, strict git ignore rules, scoped low-privilege dev credentials, and expiration where possible. Local convenience is fine; production parity for sensitive secrets is not.
How often should we rotate database and API credentials?
Use risk-based frequency. High-impact production credentials should rotate more often and always have emergency revocation paths. Start with practical intervals your team can execute reliably, then tighten as automation improves.
What’s the difference between KMS, secret manager, and vault?
KMS focuses on cryptographic key operations. Secret managers/vaults handle secret lifecycle tasks such as storage, access policy, retrieval, rotation workflows, and audit trails. Many architectures use both.
How do we prevent secrets from leaking into logs?
Disable sensitive logging by default, sanitize known token patterns, enforce structured logging filters, and test redaction paths in CI. Then validate with periodic log sampling and alerting on token-like strings.
Is Kubernetes Secrets enough by itself?
Not usually for mature production needs. Kubernetes Secrets can be part of the stack, but you still need strong etcd encryption settings, identity controls, rotation workflows, and centralized audit visibility across environments.
Should contractors get direct secret access?
Only when necessary, and always with scoped, time-bound permissions plus monitoring. Prefer brokered workflows and break-glass processes over broad standing access.
What’s a realistic budget for an early-stage team?
Budget varies, but the practical framing is this: compare tooling spend against the cost of one leak-driven outage, one delayed enterprise deal, and recurring engineering toil. Small managed spend often wins in total cost.
How do we handle emergency credential revocation?
Maintain a tested runbook with clear ownership, command channel, immediate revoke steps, dependency validation, rollback procedure, and customer/internal communication templates. Drill quarterly at minimum.
What’s the minimum policy set for least privilege?
Define per-service read scopes, separate human and workload permissions, deny-by-default posture, explicit environment boundaries, and time-bound elevated access with approvals and logs.